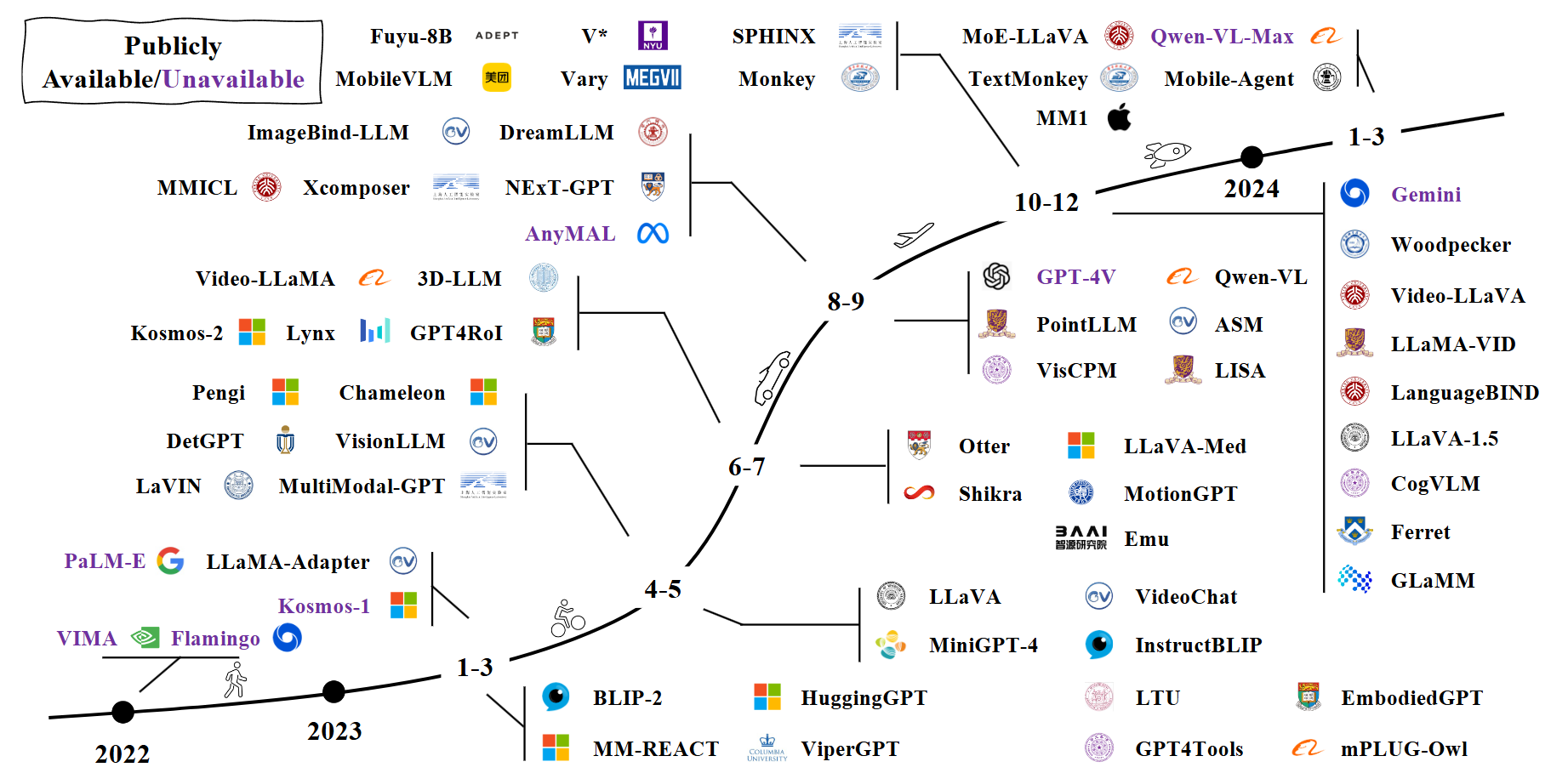
 A timeline of representative Multi-modal LLMs. We are witnessing rapid growth in this field.
A timeline of representative Multi-modal LLMs. We are witnessing rapid growth in this field.Initially heralded for their conversational capabilities, LLMs have evolved far beyond chatbots, demonstrating remarkable proficiency in understanding, generating, and reasoning with human-like language. In this article, we will highlight the latest advancements in the field with three key trends reshaping the landscape.
Large Language Models (LLMs), such as OpenAI's GPT series and Meta's LLaMA, are at the forefront of natural language processing, constantly redefining what AI can achieve. Initially heralded for their conversational capabilities, these models have evolved far beyond chatbots, demonstrating remarkable proficiency in understanding, generating, and reasoning with human-like language. In this article, we will highlight the latest advancements in the field with three key trends reshaping the landscape.
Multimodal Large Language Models (MLLMs) are an exciting blend of Large Language Models (LLMs) and Large Vision Models (LVMs), bringing together the best of both worlds. LLMs are great at understanding and generating text, showing amazing abilities like following instructions and reasoning through problems. But here's the thing—they're "blind" to images, videos, and other types of visual information. On the flip side, LVMs are awesome at "seeing" and understanding visuals, but they aren't great at reasoning.
That's where MLLMs come in. They combine these strengths, letting models handle text, images, and even videos or audio seamlessly. With new techniques like multimodal instruction tuning and models with billions of parameters, MLLMs can now do incredible things like writing website code based on a picture, understanding memes, or solving maths problems without relying on OCR.
This field has been growing super fast, especially since the release of GPT-4, with new models popping up almost every month. And just recently, Gemini updated support of reading images within a PDF file. MLLMs are being used in everything from medical image analysis to creating agents that can interact with the real world. They're also getting smarter about languages and giving users finer control over how they interact with the model. It's a rapidly evolving space, full of potential to change how we use AI in everyday life.
A timeline of representative Multi-modal LLMs. We are witnessing rapid growth in this field.
As the demand for AI applications grows, so does the need for efficient models that can perform well without requiring massive computational resources. This is especially useful when you have really sensitive data and don't want to send it to centralised servers for processing. By running efficient models locally on edge devices, organizations and individuals can ensure greater data privacy and security.
Knowledge distillation has emerged as a leading technique to address this challenge. This process involves training a smaller "student" model to mimic the behaviour of a larger, more complex "teacher" model. By learning from the teacher's outputs, the student model can achieve comparable performance while being faster and lighter.
Recent advancements in knowledge distillation are pushing the boundaries of efficiency. For example, OpenAI introduced GPT-4o mini in July, 2024. Although OpenAI has not disclosed any details, many researchers believe it is a knowledge-distilled version of the GPT-4o model. GPT-4o mini not only offers comparable performance but also comes at a "bargain price". Specifically, the pricing is $0.15 per million input tokens and $0.60 per million output tokens. It is even more than 60% cheaper than GPT-3.5 Turbo!
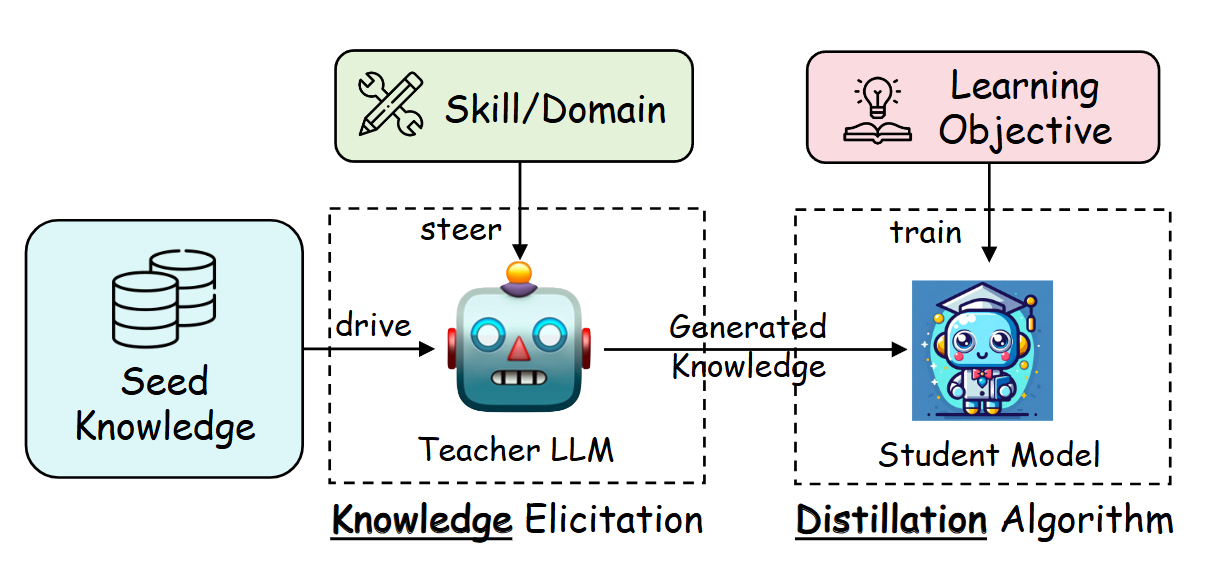 An illustration of a general pipeline to distill knowledge from a large language model to a student model.
An illustration of a general pipeline to distill knowledge from a large language model to a student model.
Researchers are continuously optimizing this technique to preserve not just the accuracy of the teacher model but also its reasoning capabilities, generalization power, and domain-specific knowledge. This has led to the development of compact LLMs that can run on edge devices, such as smartphones or embedded systems, without sacrificing performance.
One of the most transformative advancements in Large Language Models (LLMs) is their ability to handle increasingly complex reasoning tasks. Researchers and developers have been enhancing the reasoning capabilities of these models using innovative techniques like Chain-of-Thought (CoT), Tree-of-Thought (ToT), Retrieval-Augmented Generation (RAG). One specialized advancement incorporating these techniques, which you may already know, is OpenAI o1.
Chain-of-Thought (CoT) prompting is a powerful method where LLMs are encouraged to break down complex problems into smaller, manageable steps. Instead of generating a single-shot answer, the model processes the query in a sequential, logical manner, mirroring human reasoning.
Building upon CoT, Tree-of-Thought (ToT) extends the sequential reasoning paradigm by exploring multiple potential reasoning paths simultaneously. ToT allows LLMs to consider and evaluate various solutions before arriving at the best one.
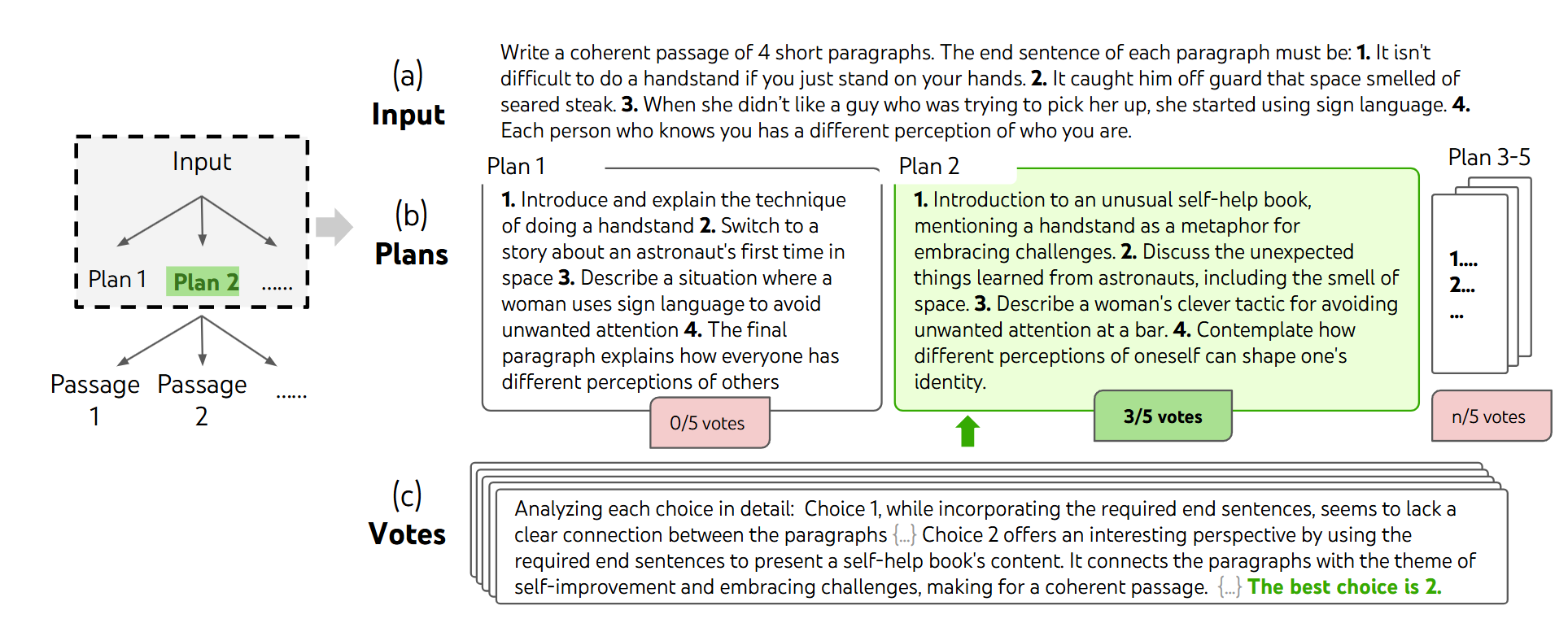 In a typical ToT pipeline, the LM samples 5 different plans given the input, and votes 5 times to decide which plan is the best.
In a typical ToT pipeline, the LM samples 5 different plans given the input, and votes 5 times to decide which plan is the best.
CoT and ToT rely solely on generated contents of LLMs. Can we augment the results with external information relevant to input prompt? Retrieval-Augmented Generation (RAG) is transforming how LLMs access and utilize knowledge by combining pre-trained insights with real-time retrieval of relevant data from external databases, knowledge bases, or the web during inference. This hybrid approach empowers LLMs to generate responses that are not only accurate but also contextually relevant, comprehensive, and up-to-date.
OpenAI’s "o1" framework reportedly integrates elements of CoT, ToT, and RAG, along with proprietary innovations in structured knowledge representation and advanced reasoning protocols. Although the details of "o1" remain proprietary, its impressive performance underscores the importance of advancing LLM reasoning capabilities.
At the center of this AI revolution, NetMind.AI continues to stand out as a pioneering force, driving breakthroughs in the field. With our cutting-edge decentralised compute network, NetMind.AI provides more than just a platform—it serves as the foundational infrastructure for the future of AI innovation. By enabling scalable, efficient, and secure compute capabilities, NetMind empowers researchers, developers, and enterprises to push the boundaries of what's possible with AI.
In addition, NetMind supports extensive API integrations for a wide array of language models like Llama and Qwen, making it a versatile and accessible solution for diverse AI applications. Whether it's leveraging state-of-the-art multimodal capabilities, deploying compact models for edge devices, or enhancing reasoning through advanced techniques, NetMind ensures seamless access to the tools and infrastructure needed to harness the full potential of modern AI.
User-Agent: