For digital finance companies, collecting repayments efficiently while maintaining customer trust is a constant balancing act.
In the competitive credit card market of Latin America, one of the region’s leading digital lenders faced exactly this challenge: millions of users, strict compliance boundaries, and the need for smarter, more respectful engagement.
Through our AI consulting service, we helped the client develop and deploy an Offline Reinforcement Learning (Offline RL)–based decision engine.
What did it do?
It transformed their debt collection process from rule-based heuristics into an intelligent, data-driven orchestration of policy, achieving:
Debt collection is a delicate process with strict regulations on contact frequency, and the objective is to maximize repayment while minimizing user disruption.
Traditional approaches rely heavily on empirical scheduling, which are difficult to scale or adapt across different user segments.
The client’s existing operation involved 552 different contact actions, a massive, unevenly distributed action space.
While some combinations of marketing channels, contact timing, user segments and schedule templates performed well, many others were underused.
What adds to the challenge?
Maximizing a single day’s outcome probably won't guarantee long-term optima, as the decision sequence across the billing cycle must be modeled holistically.
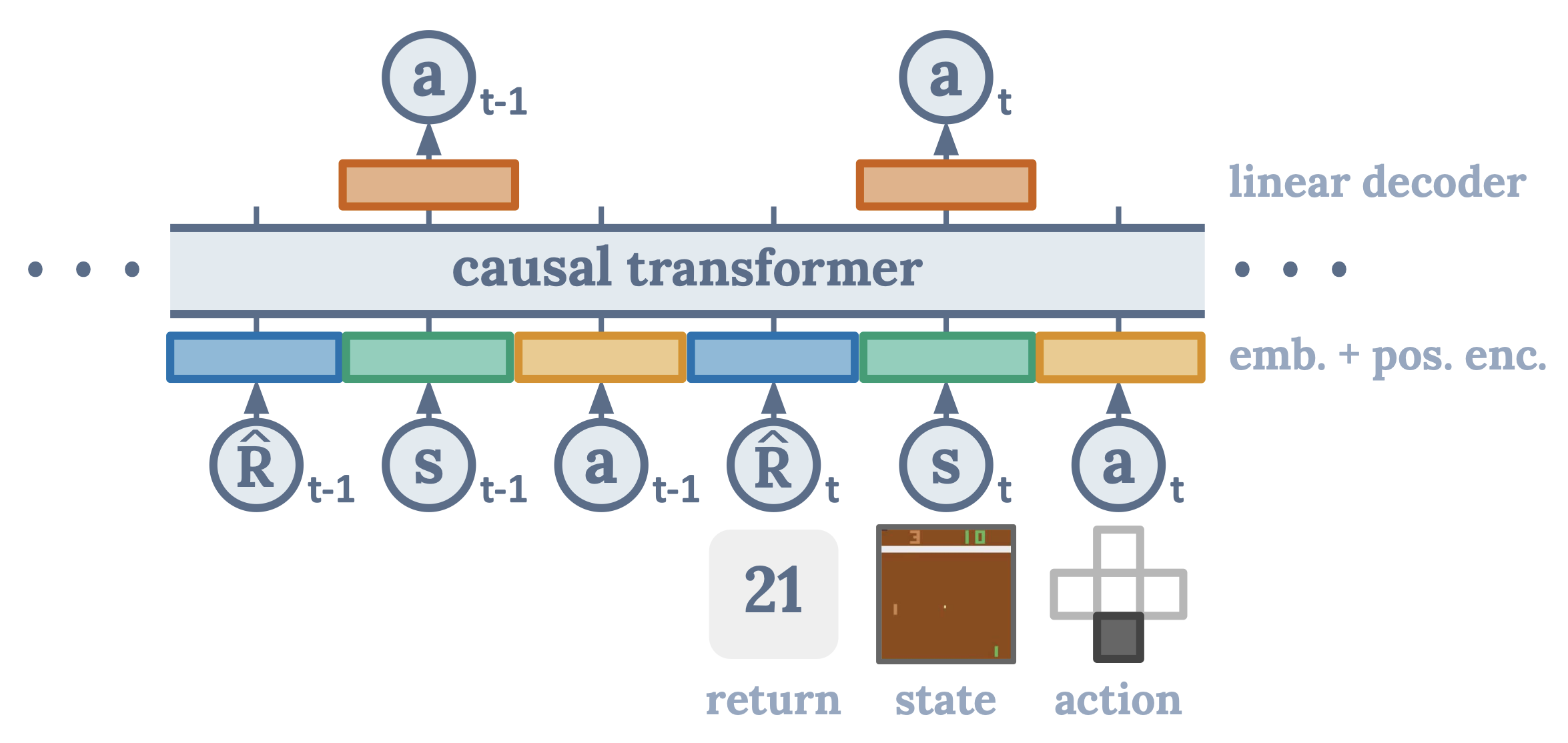
Decision Transfomer (Source: https://arxiv.org/abs/2106.01345)
To tackle this, we built a collection strategy powered by a Decision Transformer (DT) model — a state-of-the-art RL model that learns the optimal sequence of actions from historical data without requiring online interactions.
How is it distinct?
Although it shares the Transformer architecture with modern language models like GPT or T5, the Decision Transformer uses this architecture in a different way.
Instead of predicting the next word in a sentence, it predicts the next decision in a sequence, conditioning on past states, actions, and desired outcomes (rewards).
This allows it to capture long-term dependencies and optimize entire action sequences over time, rather than isolated steps.
The DT model learns from historical “state–action–reward” sequences, where each state encodes over 46 customer features, including region, gender, risk segment, repayment history, holidays, payroll cycles, and more. Each action represents a concrete outreach decision, aligning with the client's existing 552 actions.
Is compliance a big concern for you?
To ensure compliance, our model also uses a valid action mask that blocks invalid or non-compliant actions (such as exceeding contact limits).
There's more.
For new clients and business lines, we also provide a layered action design methodology that goes beyond legacy action definitions to our client.
Instead of directly inheriting hundreds of ad-hoc templates, we decompose actions along key dimensions: marketing channel, content type, and customer attributes, and then recombine them through configurable rules.
This approach maintains interpretability while achieves the following:
Our DT model operates through a two-stage output head:
During deployment, we incorporate exploration via Top-N or ε-greedy sampling and penalty on repetition to avoid over-contacting the same customer, encouraging action diversity and long-term optimization.
There's a bonus.
Such exploration data is also collected to enrich the offline training dataset, supporting continuous learning.
As we mentioned before, the DT model is trained entirely offline, using only existing interaction logs. In this way, we can mitigate both compliance risks and the cost of online experimentation, as they are excessively expensive in financial cases.
By measuring evaluation metrics such as sequence consistency and action prediction accuracy, we ensure our trained models are reliable offline proxies before A/B testing on small online segments.
If you wonder if DT is just a casual choice, we did benchmark our solution against other methods like recurrent Q-learning variants (e.g., DRQN) and off-policy evaluation (OPE) methods (e.g., fitted Q evaluation (FQE)), and found DT to be more stable and data-efficient.
Across multiple A/B test batches, the strategy of our DT model consistently improved minimum repayment completion rates by 15–25% compared to our customer's linUCB baseline.
More importantly, the model led to fewer redundant and invalid contacts thanks to the action mask and repetition penalty tricks. Our customer's business teams reported noticeably smoother and more considerate outreach schedules, aligning with their operation goals and regulations.
During training, the reward function targets the minimum repayment completion while incorporating weighting that balances recovery rate, cost, and user experience. This design makes the system highly adaptable and flexible. If necessary, the model can be trained with adjustments to the reward function so that the strategy can be more aggressive or conservative.
Consequently, our final delivery of the solution included:
Again, is privacy a big concern to you?
Beyond the model itself, we ensured privacy and compliance from the ground up. The entire solution can be deployed within the client’s private cloud, ensuring data sovereignty and regulatory compliance. All components, including data ingestion and model inference, operate within the client’s secure domain, with encrypted transmission and full auditability.
This debt collection case is just one example of how our AI consulting service at NetMind helps organizations turn complex operational challenges into intelligent, data-driven decision systems.
From financial services to retail, logistics, and beyond, we work with clients to design, train, and deploy customized AI solutions that optimize performance while ensuring compliance and long-term scalability.
Book a demo with our SVP Stacie Chan to turn our AI technology into your AI solutions!
User-Agent: