In a recent presentation at CVPR2025, researchers Kaiming He, Yann LeCun, and their team challenged a long-held assumption in deep learning: that normalization layers are indispensable. Their new approach introduces the Dynamic Tanh (DyT) function, an element-wise operation that can replace traditional normalization layers in Transformer models.
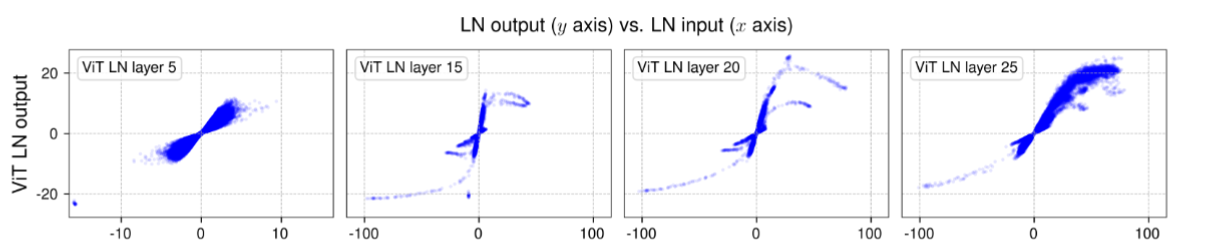
Normalization layers—such as Batch Normalization, Layer Normalization, Instance Normalization, and Group Normalization—have been a staple in neural network design for over a decade. They are known for accelerating convergence, stabilizing training, and improving overall performance. In Transformer models, Layer Normalization (LN) is nearly ubiquitous. However, the team behind DyT observed that the input-output mapping of these normalization layers, particularly in deeper layers of Transformers, often follows an S-shaped curve reminiscent of the tanh function.
This observation led to a bold idea: if the non-linear "squashing" effect of normalization is the key to its success, why not replicate it directly with a simpler, element-wise operation?
DyT is designed to mimic the effect of normalization layers without computing statistics across tokens or batches. Instead, it applies a learnable scaling factor followed by a tanh-like nonlinearity to each element in the input. Here’s a simplified pseudocode to illustrate the concept:
# input x has the shape of [B, T, C]
# B: batch size, T: tokens, C: dimension
class DyT(Module):
def __init__(self, C, init_α):
super().__init__()
self.α = Parameter(ones(1) * init_α)
self.γ = Parameter(ones(C))
self.β = Parameter(zeros(C))
def forward(self, x):
x = tanh(self.alpha * x)
return self.γ * x + self.βHere, alpha is a learnable scalar parameter that allows the input to be scaled differently according to its range. The vector gamma is simply initialised as an all-ones vector, and beta as an all-zero vector. For the scaler parameter alpha, apart from LLM training, a default initialisation of 0.5 is usually sufficient.
DyT shouldn't be considered a new type of normalization layer because it processes each input element individually during the forward pass without calculating any statistics or aggregating data. Instead, it still achieves the normalization effect by non-linearly squashing extreme values, while almost linearly transforming the input's central range. This design eliminates the need to compute per-token or per-batch mean and variance, potentially streamlining both training and inference.
The researchers conducted a wide range of experiments to compare DyT with traditional normalization layers across several tasks:
One of the key insights from the study is that while the majority of inputs to the normalization layers remain in a quasi-linear regime, the few outliers in the “extreme zones” are what really benefit from the non-linear squashing provided by tanh. The learnable parameter in DyT adapts during training to approximate the effect of scaling the input activations, helping to stabilize training without the overhead of computing statistics.
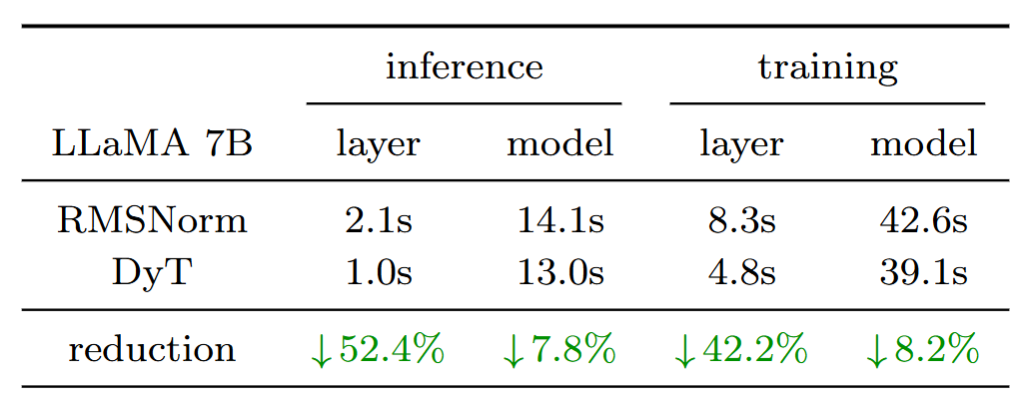
Another important advantage of DyT is its computational efficiency. Benchmarks comparing DyT with RMSNorm on LLaMA 7B demonstrated significant reductions in forward and backward pass latency, particularly in BF16 precision. This efficiency could prove especially beneficial for high-performance or resource-constrained environments.
The introduction of the Dynamic Tanh function represents a paradigm shift in how we think about normalization in neural networks. By showing that a simple, element-wise operation can replace complex normalization layers while preserving—or even improving—performance, the work may open new avenues for designing faster and more efficient AI models.
Stay tuned as we watch how this innovation influences future research and applications across computer vision, natural language processing, and beyond!
Paper Link: https://arxiv.org/abs/2503.10622
Project Page: https://jiachenzhu.github.io/DyT/