DeepSeek's Group Relative Policy Optimisation (GRPO) has shown promising results in solving some of reinforcement learning's persistent challenges. What makes GRPO so powerful, and how can you implement it in your projects? In this article, we will explore the core principles behind GRPO and introduce a tutorial project that lets you experience GRPO first-hand!
Before delving into GRPO, it's worth understanding why we need alternatives to conventional reinforcement learning approaches. Traditional methods like PPO (Proximal Policy Optimisation) rely on two key components:
1. A Policy model that generates outputs;
2. A Critic model that estimates the value of those outputs.
However, this dual-model approach creates several challenges for training Large Language Models:
• Memory inefficiency: Managing two models consumes substantial GPU memory, especially on the scale of thousands of billions of parameters for a Large Language Model;
• Training instability: The critic often struggles to provide consistent value estimates. This problem may be less noticeable in smaller environments, but for large corpora of training data, it is significantly amplified;
• Complex implementation: Balancing policy and critic training requires careful tuning of hyperparameters, which is usually not applicable in terms of training Large Language Models. There is no way you can feasibly perform extensive hyperparameter sweeps at that scale.
These limitations become especially pronounced when working with large language models, where even small optimisations can mean the difference between feasible and impossible training runs.
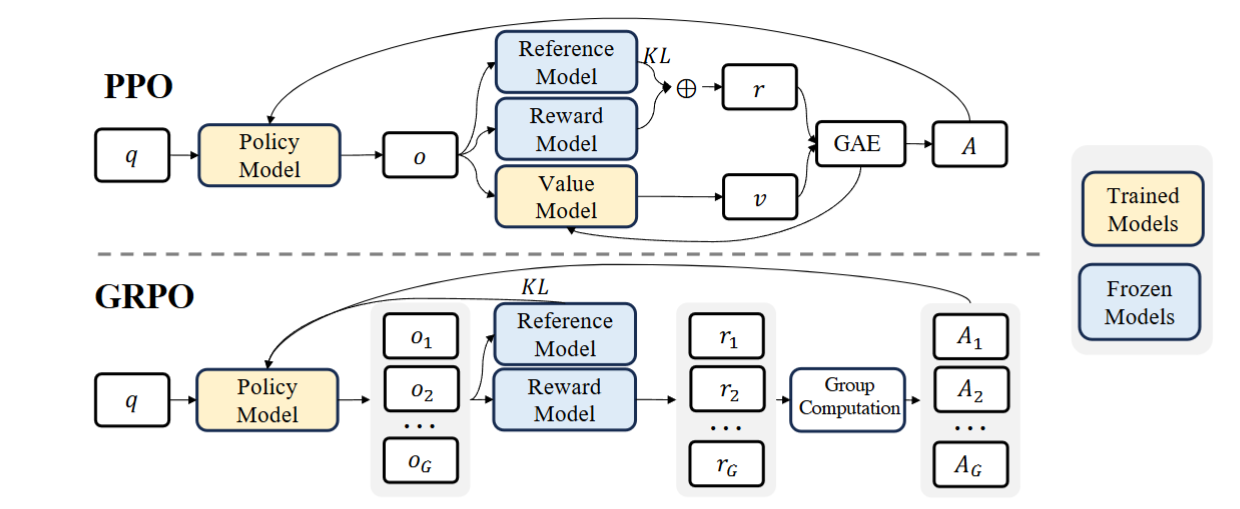
GRPO takes a fundamentally different path by getting rid of the Critic model. Instead of trying to estimate absolute values for outputs, it focuses on relative comparisons within groups of samples. More specifically, GRPO uses the average reward of multiple sampled outputs, produced in response to the same question, as the baseline. For each question, GRPO samples a group of outputs from the old policy and then optimizes the policy model by maximizing a newly designed objective. This simple but profound shift makes GRPO more powerful even without the Critic model.
Demonstration of PPO and GRPO. GRPO foregoes the value model, instead estimating the baseline from group scores, significantly reducing training resources.
GRPO also delivers substantially increased training stability. Critic models in traditional RL are notoriously difficult to train properly - they must learn to accurately estimate values across a wide range of potential outputs, a task that grows in complexity with the richness of the output space. Language models, with their vast potential output distributions, make this especially challenging. By replacing absolute value estimation with relative comparison between outputs, GRPO establishes a more reliable learning signal. This comparative approach tends to be more robust to outliers and easier to calibrate, resulting in more consistent training dynamics and fewer divergence issues that plague traditional methods.
For more details about GRPO, we recommend our readers to read their original paper, available in Arxiv.
The Hundred-Page Language Models Book has recently been updated with a tutorial code showing GRPO through clear, well-documented code. Rather than treating the algorithm as a black box, this project breaks it down into comprehensible components and implements each from scratch.
The project uses Qwen2.5-1.5B-Instruct—a relatively small language model by today's standards—and transforms it into a competent mathematics problem solver using the GSM8K dataset. This practical implementation makes GRPO accessible to developers without enterprise-grade computing resources.
By working through this tutorial, you'll gain both theoretical understanding and practical experience with one of the most promising reinforcement learning techniques in today's LLM landscape. Whether you're looking to enhance your own models or simply better understand the technology powering the latest AI systems, this hands-on project offers valuable insights into the future of language model training.
Building on the promising advancements of GRPO and the hands-on tutorial showcased above, we are excited to announce that DeepSeek-V3-0324 is now live on NetMind. With NetMind's scalable, high-performance AI infrastructure, developers can now access this cutting-edge model more easily than ever. Embrace this opportunity to enhance your projects and explore new horizons in language model training with DeepSeek-V3-0324 on NetMind.
Considering leveraging a powerful resource for your computational needs? NetMind offers access to a wide selection of scalable, high-performance GPU instances and clusters at competitive prices, freeing you from the hassles of hardware management and scalability. Join NetMind today and reach new heights in GPU computing!