
What if we told you that teaching AI to play simple games like poker and tic-tac-toe could make it dramatically better at solving complex maths problems through reasoning? That's exactly what researchers discovered in a fascinating new study called SPIRAL, where they used competitive gaming to unlock powerful reasoning abilities in language models.
Current AI systems face a fundamental challenge when it comes to reasoning. While they excel at following patterns they've seen before, they struggle with truly novel problems that require genuine thinking. Most approaches to improving AI reasoning rely on feeding models thousands of carefully crafted examples with human-provided solutions—an expensive and time-consuming process that doesn't scale well.
The researchers behind SPIRAL asked a provocative question: What if we could teach AI to reason without any human-created training data at all?
SPIRAL takes a radically different approach. Instead of studying maths textbooks, the AI learns by playing competitive games against continuously improving versions of itself. In this process, the AI has to improve its strategy through reasoning. The researchers chose three simple but strategically rich games:
•Tic-Tac-Toe for spatial reasoning and pattern recognition
•Kuhn Poker for probabilistic thinking and decision-making under uncertainty
•Simple Negotiation for strategic optimisation and multi-step planning
The key insight, according to the authors, is that these games naturally force the development of core reasoning skills that transfer beyond gaming.
The results were striking. An AI model trained exclusively on Kuhn Poker—never seeing a single maths equation during training—improved its mathematical reasoning performance by 8.6% and general reasoning by 8.4%. Even more impressively, this self-taught approach outperformed models that had been trained on 25,000 expert game examples.
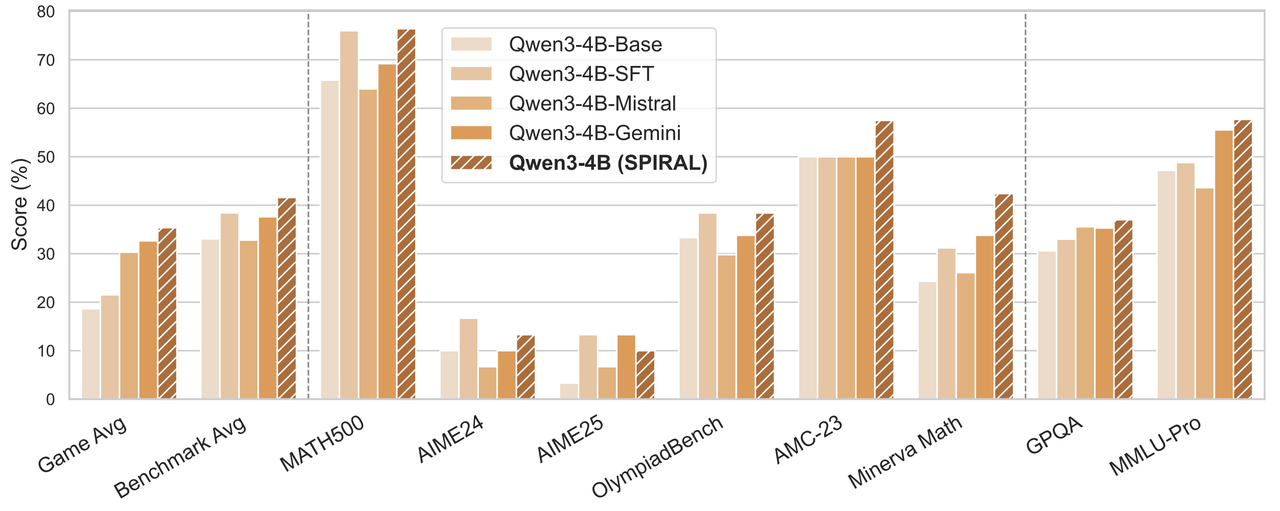
SPIRAL achieves consistent improvements over base models across game performance and reasoning benchmarks. It also surpasses SFT on expert game trajectories and RL baselines trained against fixed opponents (Mistral and Gemini).
What makes SPIRAL particularly clever is its use of self-play. Unlike training against fixed opponents (which leads to exploitation of specific weaknesses), competing against evolving versions of itself creates an ever-adapting curriculum. As the AI improves, so does its opponent, maintaining the perfect level of challenge needed for continued growth, which also incentives critical reasoning for improving AI's strategy.
When researchers analysed what was happening inside the AI's "mind," they discovered three powerful reasoning patterns emerging:
1.Case-by-Case Analysis: Breaking complex problems into manageable scenarios
2.Expected Probability Calculation: Weighing probabilities and potential outcomes
3.Pattern Recognition: Identifying underlying structures and regularities
These cognitive tools, honed through competitive gameplay, proved remarkably effective when applied to mathematical problems.
This approach also revealed something crucial: without proper training techniques, AI models would actually get worse over time, abandoning complex reasoning in favor of simple responses. For example, if the opponent is a fixed random agent which always take a random action, the training would easily collapse by generating empty thinking content. The researchers also developed a technique called "Role-conditioned Advantage Estimation" to prevent this "thinking collapse"—ensuring models continue generating detailed reasoning even after hundreds of training rounds.
SPIRAL represents a paradigm shift in how we think about developing AI reasoning. By harnessing the natural pressure of competition, we can create systems that discover their own reasoning strategies rather than simply imitating human examples. This approach is:
•Scalable: No need for expensive human annotation
•Generalisable: Skills transfer across domains automatically
•Autonomous: The system improves through self-generated challenges
The team showed that training on multiple games simultaneously creates synergistic benefits—each game develops different cognitive strengths that combine to create more robust reasoning abilities. Even more remarkably, when they applied their technique to already-strong reasoning models distilled from DeepSeek-R1, they still achieved meaningful improvements.
This research opens exciting possibilities for the future of LLMs. If simple games can unlock such powerful reasoning abilities, imagine what more sophisticated competitive environments might achieve. The researchers envision "ecosystems of self-improving agents generating increasingly sophisticated challenges," pointing toward AI systems that continuously push their own reasoning boundaries.
Perhaps most intriguingly, this work suggests that intelligence might emerge not from sophisticated supervision but from the fundamental challenge of competition itself. In teaching AI to play games, we may have discovered a key to teaching it to think. After all, if playing poker can make an AI better at calculus, what might it do for us?
Read the paper at: https://arxiv.org/abs/2506.24119