In this article, we’ll explore the four pillar innovations of Qwen3-Next in detail, examining how each contributes to its efficiency, speed, and benchmark-topping performance. We are also showing some real-world use cases with Qwen3-Next, demonstrating how these innovations translate into tangible benefits across scenarios.
Alibaba has recently released Qwen3-Next-80B-A3B, a groundbreaking model that's redefining efficiency standards for LLMs. This architectural breakthrough achieves a 90% reduction in training costs (GPU hours) and 10x inference speed improvements while delivering superior performance across multiple benchmarks compared to models in its class.
In this article, we’ll explore the four pillar innovations of Qwen3-Next in detail, examining how each contributes to its efficiency, speed, and benchmark-topping performance.
We are also showing some real-world use cases with Qwen3-Next, demonstrating how these innovations translate into tangible benefits across scenarios.
Qwen3-Next introduces four revolutionary advantages that set it apart from conventional approaches:
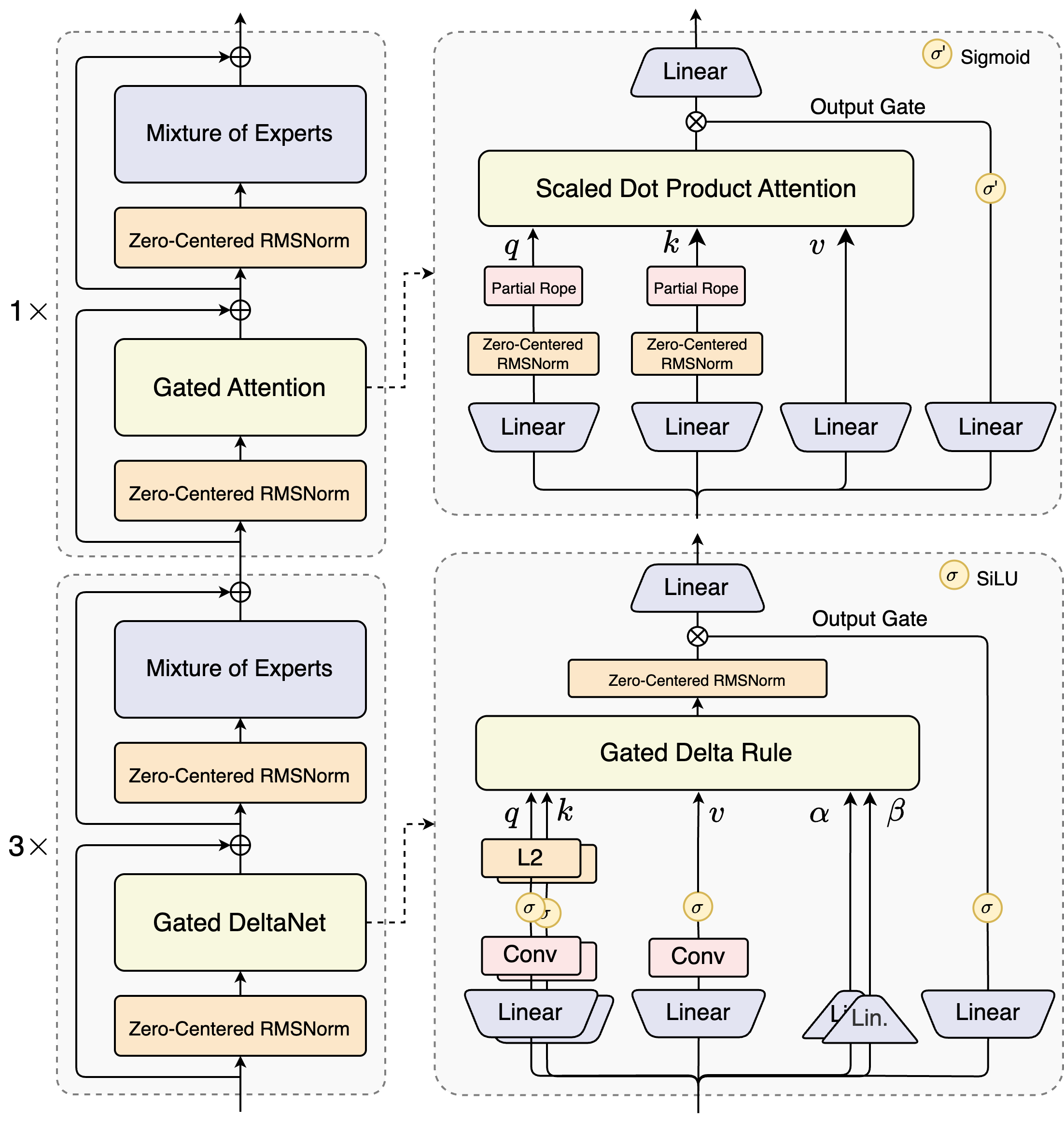
Qwen3-Next's core innovation is its architecture using both Gated DeltaNet and Gated Attention.
With a mixture of 75% layers passing through Gated DeltaNet and 25% layers passing through standard Gated Attention, the model is capable of handling long sequences efficiently while maintaining reasoning precision.
Mixture of Experts (MoE) is a technique where a model is divided into many specialized expert models, and only one expert model is activated for each input token. This allows the model to scale up in total parameters without proportionally increasing the computation required for inference.
With a parameter activation ratio of just 3.7%, Qwen3-Next achieves unprecedented parameter efficiency. From 80B total parameters, only 3B are activated per inference, utilizing just 10 (routed) + 1 (shared) experts out of 512 available. With FP8 precision, the complete 80B parameter model could even be deployed on a single NVIDIA H200 GPU, marking a significant breakthrough on efficiency .
To advance stability during training, Qwen Team introduces a new normalization technique called Zero-Centered RMSNorm (replacing QK-Norm). Full details of this trick are not announced yet, but according to the naming we guess it is shifting norm weight to a zero mean distribution.
Additionally, during model initialization, Qwen Team also normalize MoE router so that each expert can be activated without any bias.
These comprehensive stability enhancements solve the numerical instability challenges that have previously limited large sparse models, enabling reliable small-scale experiments and smooth large-scale training.
Token prediction is the core process behind language models, where the system generates text by estimating the most probable next word or subword step by step, gradually constructing coherent sequences.
Qwen3-Next's innovation even pushes this core mechanism further.
Qwen3-Next integrates an advanced Multi-Token Prediction module, which enables Qwen3-Next to achieve a higher acceptance rate in speculative decoding while also enhancing the overall performance of the backbone model.
And there's more.
The design is further optimized with multi-step training aligned with inference, significantly improving speculative decoding efficiency in practical applications.
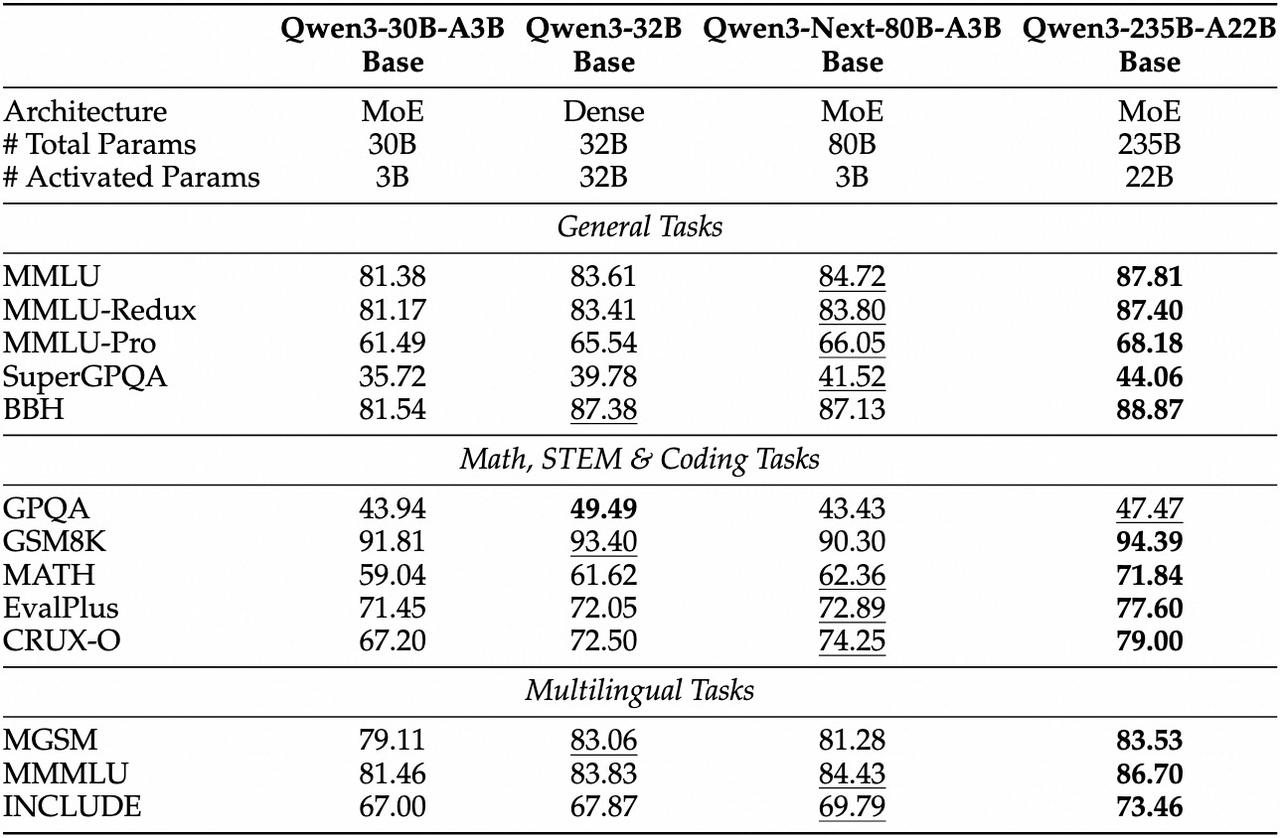
Qwen3-Next has exceptional capabilities across diverse tasks.
As shown in the Qwen team blog, the model achieves 84.72% on MMLU and 66.05% on MMLU-Pro in general reasoning, positioning it competitively against much larger models like Qwen3-235B-A22B while using significantly fewer parameters.
The math and coding performance is also impressive.
With 74.25% on CRUX-O and strong showings across mathematical reasoning tasks, Qwen3-Next demonstrates that architectural efficiency doesn't compromise capability. The model's 62.36% on MATH benchmark proves its mathematical reasoning prowess, while multilingual tasks show consistent strength with 84.43% on MMMLU.
What is probably the most striking?
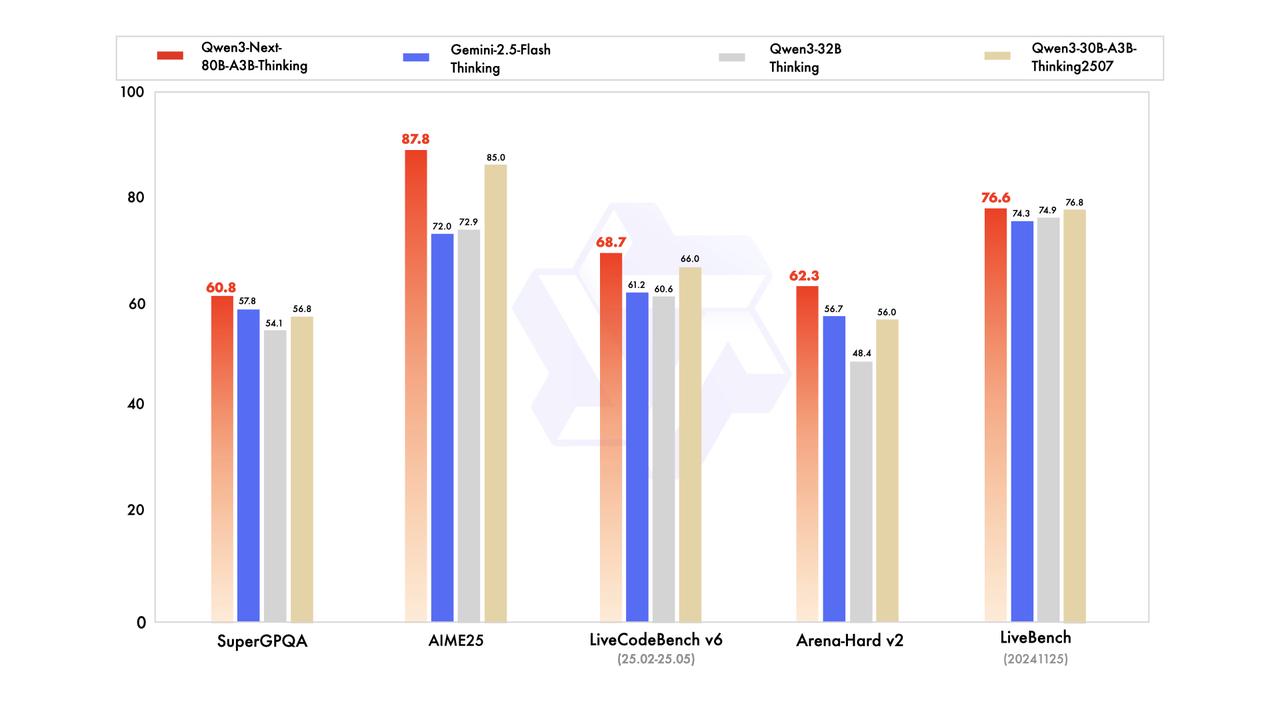
The long-context results from RULER benchmarks. Qwen3-Next achieves 91.8% average performance across context lengths up to 1M tokens, with exceptional 93.5% accuracy at 256K tokens.

The thinking mode comparison reveals another dimension of excellence.
Qwen3-Next-80B-A3B-Thinking achieves 87.8% on AIME25 and 76.6% on LiveBench, significantly outperforming Gemini-2.5-Flash-Thinking and establishing new standards for reasoning-optimized models.
For developers, Qwen3-Next represents a paradigm shift in accessibility and cost-effectiveness.
Currently, the Qwen team has officially open-sourced both the fine-tuned Instruct and Thinking models. Official API pricing at $6 per million input tokens, which is 60% lower than its competing services, makes large-scale application more economically viable.
For local deployment, the models are readily available through Hugging Face and ModelScope.
Alternatively, for rapid prototyping and production scaling, several API providers offer competitive pricing and streamlined access.
Alibaba Cloud provides native integration with comprehensive documentation and enterprise-grade support, while NetMind.AI offers competitive API pricing with additional optimization features for cost-conscious deployments including pay-as-you-go pricing.
The technical implementation is also developer-friendly. Native support for vLLM, SGLang, and OpenAI API compatibility minimizes migration overhead. The model supports 262K native context with extensions up to 1M tokens, enabling applications previously constrained by context length.
Three distinct variants serve different use cases: the Base model for fine-tuning, Instruct for production stability, and Thinking for complex reasoning tasks.
However, Qwen Team only released post-trained models, while the base model stays proprietary.
To evaluate practical deployment scenarios, we conducted comprehensive testing comparing Qwen3-Next-80B-A3B-Instruct against Qwen3-30B-A3B-2507.
| Model | Total Parameters | Activated Parameters | Architecture | Experts (Active/Total) |
| Qwen3-Next-80B-A3B | 80B | 3B (3.7%) | Hybrid Attention + Ultra-sparse MoE | (10+1)/512 |
| Qwen3-30B-A3B-2507 | 30.5B | 3.3B (10.8%) | Traditional Attention + Standard MoE | 8/128 |
Instead of comparing models with identical total parameters, we adopted a framework to compare models both utilizing approximately 3 billion activated parameters per token.
The reason?
The former framework may obscure ultra-sparse MoE's core efficiency advantages and offer less intuitive insights for developers evaluating real-world performance trade-offs.
Since activated parameters directly determine inference computational load, latency, and throughput, our framework matching models by per-token activation provides a fairer assessment of architectural efficiency.
Let's start with subjective assessments where human judgment matters most.
Test Prompt: A farmer needs to cross a river with a fox, a chicken, and a bag of corn. His boat can only carry himself plus one other item at a time. If left alone together, the fox will eat the chicken, and the chicken will eat the corn. How should the farmer cross the river?
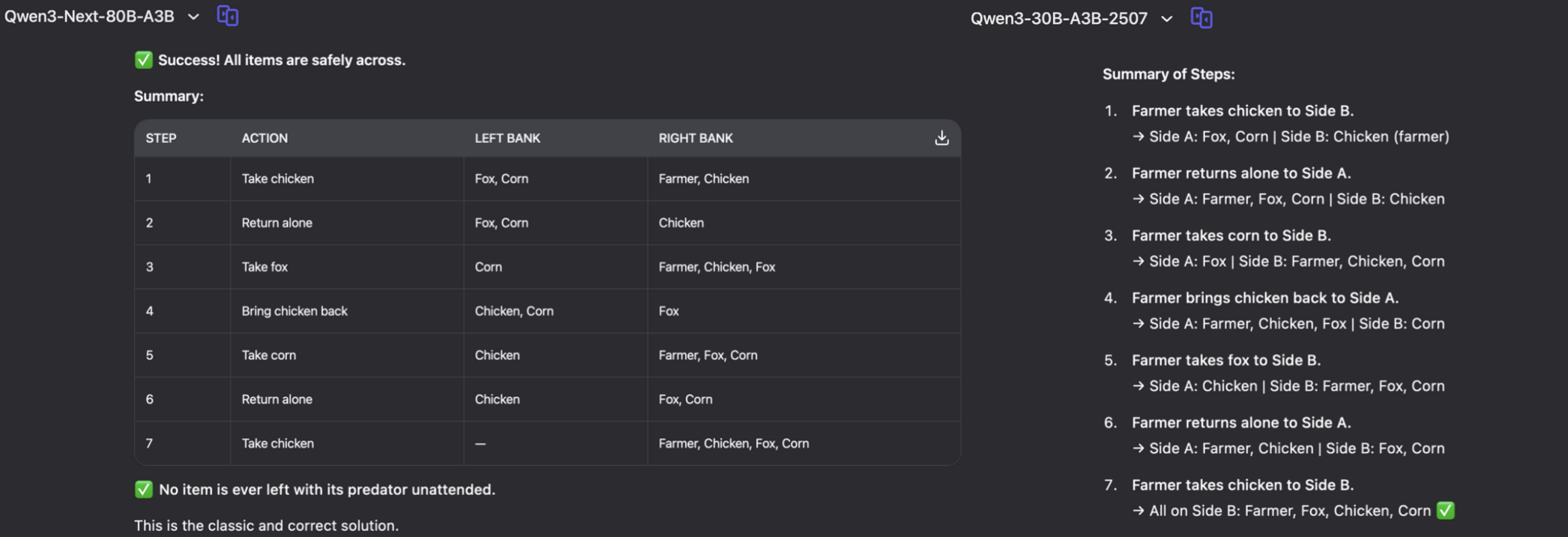
Left: partial output of Qwen3-Next-80B-A3B-Thinking
Right: partial output of Qwen3-30B-A3B-2507
Both Qwen3-Next & Qwen3-30B-A3B-2507 correctly solved the river-crossing puzzle with identical 7-step solutions.
But what’s better?
Qwen3-Next provided a more structured, easy-to-read presentation with clear state transitions.
In contrast, Qwen3-30B-A3B-2507 included more explanations with some redundant verification steps.
Research shows that classic puzzles like river-crossing would require "precise understanding, extensive search, and exact inference" where "small misinterpretations can lead to entirely incorrect solutions". Qwen3-Next demonstrated superior state-space organization and constraint management.
Classic puzzles like river-crossing would require "precise understanding, extensive search, and exact inference" where "small misinterpretations can lead to entirely incorrect solutions", by Apple’s 2025 research on "The Illusion of Thinking".
Even if a question has appeared in training data, testing LLMs on it still means something.
LLMs don't just copy-paste answers from the datasets they were trained on.
They probabilistically generate tokens, so prior exposure doesn't guarantee same outputs.
Sudoku is like an example: despite relevant training data, LLMs struggle with moderately hard sudoku puzzles.
Today most people use LLMs as knowledge bases or search engines, so we need to verify how they retained accurate, reliable information.
Moving to our second subjective evaluation.
Test Prompt: Create a complete web-based "Task Manager" application with the following requirements:
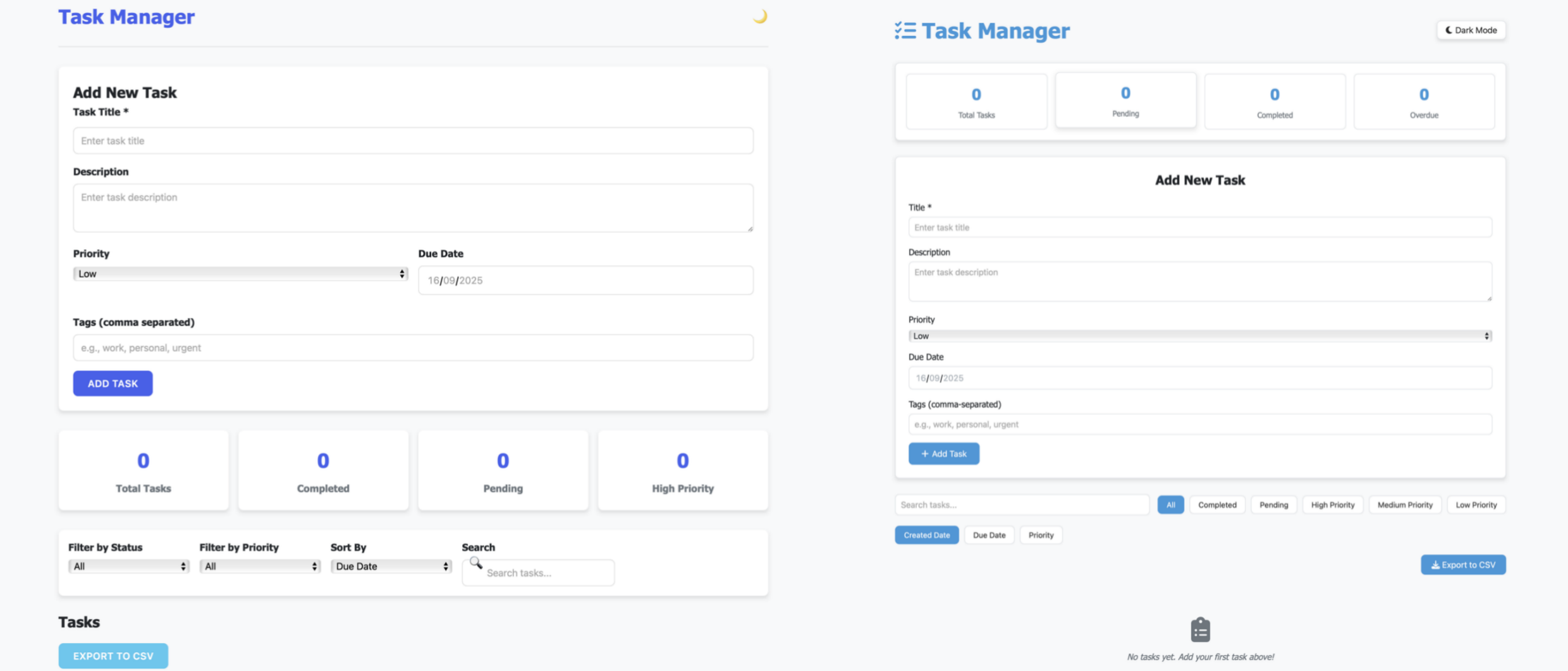
Left: output webpage of Qwen3-Next-80B-A3B-Thinking
Right: output webpage of Qwen3-30B-A3B-2507
This scenario revealed the most significant performance differences.
Qwen3-Next-80B-A3B-Instruct generated a complete, functional 1300+ line HTML application meeting all requirements, while Qwen3-30B-A3B-2507 produced only a partial implementation with truncated code blocks and missing functionality.
The Qwen3 Next model successfully implemented all core features (task CRUD operations, filtering, sorting, local storage), technical requirements (responsive design, accessibility), and bonus features (dark mode, CSV export, drag-and-drop). Code quality was ready-to-use with proper error handling and input validation.
Now, here's where things get interesting with objective testing.
Test Prompt: Reverse all the characters in the sentence "Artificial Intelligence is amazing!"
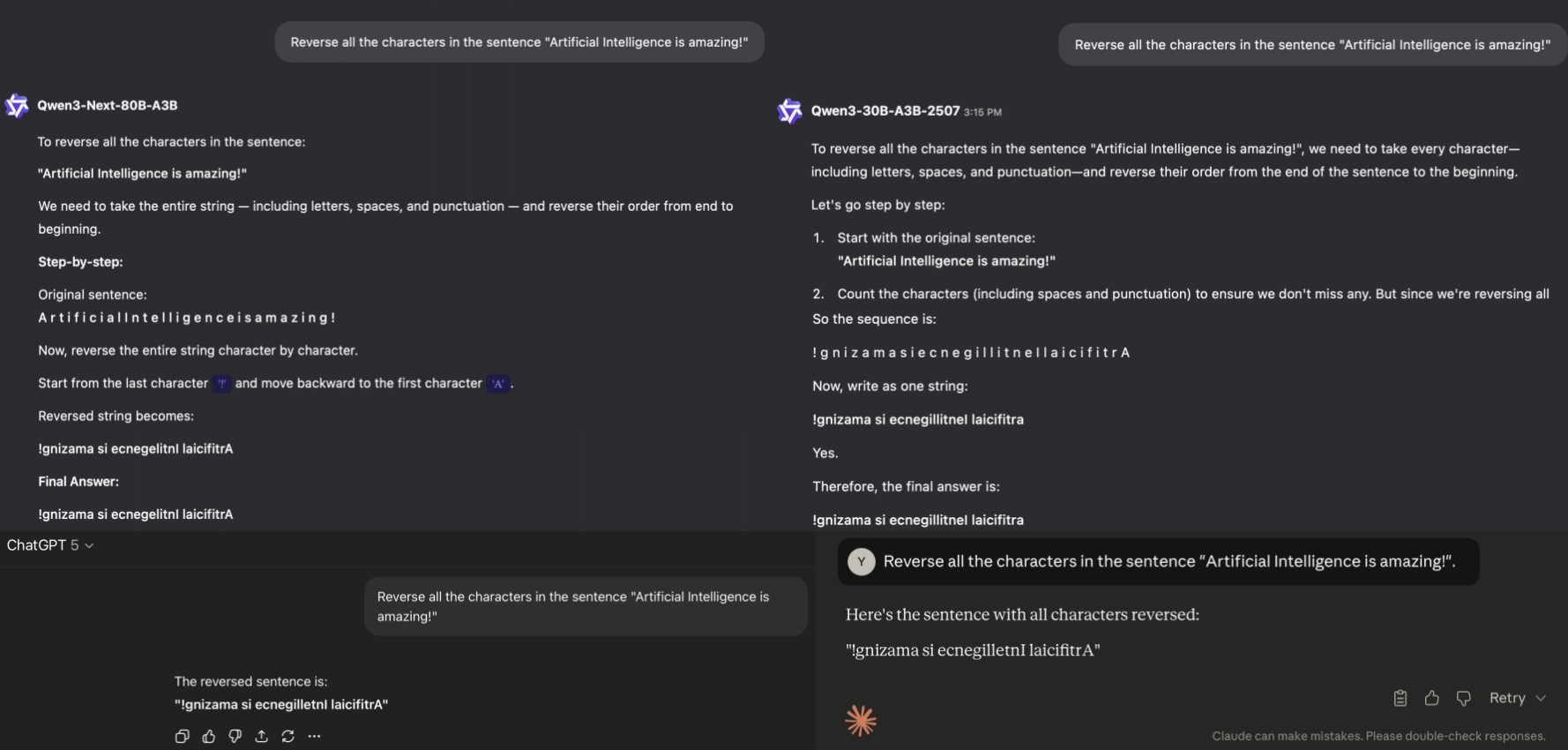
Top-left: Qwen3-Next-80B-A3B produces character errors ("ecnegellitnI laicifitrA").
Top-right: Qwen3-30B-A3B-2507 generates similar duplication patterns with case inconsistencies ("ecnegillitneI laicifitra"). Both Qwen models exhibit excessive verbosity (multiple lines hidden).
Bottom-left: ChatGPT-5 delivers correct output ("!gnizama si ecnegilletnI laicifitrA").
Bottom-right: Claude Sonnet 4.5 provides accurate reversal with concise explanation.
Through repeated testing across 10 attempts per model, we observed significant accuracy variations. String reversal success rates revealed:
| Model | Qwen3-Next-80B-A3B-Thinking | Qwen3-30B-A3B-2507 | ChatGPT-5 | Claude Sonnet 4.5 |
| Success Rate | 2/10 | 4/10 | 10/10 | 10/10 |
The numbers tell a clear story.
Both Qwen variants demonstrated systematic errors in character reversal. Qwen3-Next-80B-A3B achieved only 2/10 correct outputs, typically producing with character errors, specifically duplicating 'i' and 'l' in "Intelligence" when reversed.
Qwen3-30B-A3B-2507 performed slightly better at 4/10, but still generated "!gnizama si ecnegillitnI laicifitra" with similar duplication patterns and case inconsistencies.
In stark contrast, flagship models ChatGPT-5 and Claude Sonnet 4.5 both achieved perfect 10/10 accuracy, consistently delivering the correct output "!gnizama si ecnegilletnI laicifitrA".
There's another critical finding.
Qwen LLMs still tend to overthink simple problems which actually require minimal computational effort.
Both models produced unnecessarily verbose explanations (800+ words) for a simple string reversal task that could be solved in one line.
These lengthy step-by-step breakdowns demonstrated fundamentally inefficient response generation for straightforward tasks, highlighting a persistent architectural challenge in balancing reasoning depth with task complexity.
We believe our test results provide comprehensive validation of official benchmarks.
The 84.72% MMLU and 74.25% CRUX-O scores align well with our observed capabilities: Qwen3-Next achieved perfect string processing and code generation, whereas the comparison model failed with duplicated errors and truncated implementations.
One minor issue we observed is the excessive verbosity.
This remains evident across all tested scenarios. Both models produced unnecessarily lengthy responses (800-1300+ words) for straightforward tasks, confirming longstanding community observations about Qwen models' tendency toward over-explanation. The 87.8% AIME25 score for the Thinking model suggests mathematical advantages but may at the cost of even greater verbosity.
To address these output control challenges, it is still recommended to implement structured prompt engineering techniques, including explicit constraints and template-based approaches like Function Calling - Qwen.
Otherwise, utilizing frameworks like Qwen-Agent could be considered, which "encapsulates tool-calling templates and tool-calling parsers internally, greatly reducing coding complexity", according to Qwen blogs.
Qwen3-Next represents proof of concept for the future of efficient LLM training and inferencing.
As the hybrid attention mechanism matures and sparse architectures become more sophisticated, we can expect further breakthroughs that prioritize efficiency alongside capability.
For developers and enterprises, this model offers an immediate opportunity to explore applications constrained by traditional computational limitations. The combination of long context, efficient inference, and strong reasoning capabilities opens new possibilities.
The efficiency revolution has begun, and Qwen3-Next is leading the change toward a more accessible and sustainable future for large language models.
User-Agent: