We're thrilled to announce that the full Qwen3.6 family is now live on the NetMind Model Library: Qwen3.6-Plus, Qwen3.6-Flash, and the open-source Qwen3.6-35B-A3B.
We're thrilled to announce that the full Qwen3.6 family is now live on the NetMind Model Library: Qwen3.6-Plus, Qwen3.6-Flash, and the open-source Qwen3.6-35B-A3B.
Alibaba's Qwen team built the 3.6 family for the real-world agent era: long-horizon planning, repository-scale reasoning, native tool use, and low-latency inference at production cost. For your OpenClaw agent, Claude Code, Cursor, internal coding assistant, or production AI workflow, you can now plug any of the three variants into NetMind with one OpenAI-compatible endpoint and start building.
The Qwen3.6 series is designed as a lineup, not a single model. Each variant solves a different real-world constraint (depth of reasoning, throughput and cost, or on-premises ownership) while sharing the same architectural DNA across the family.
All three variants share a new hybrid architecture: efficient linear attention combined with sparse mixture-of-experts routing. The practical outcome is that context length stops being a latency tax. Plus and Flash both process up to 1 million tokens on NetMind, and the open-source 35B-A3B delivers frontier-class reasoning with just 3 billion parameters active per token.
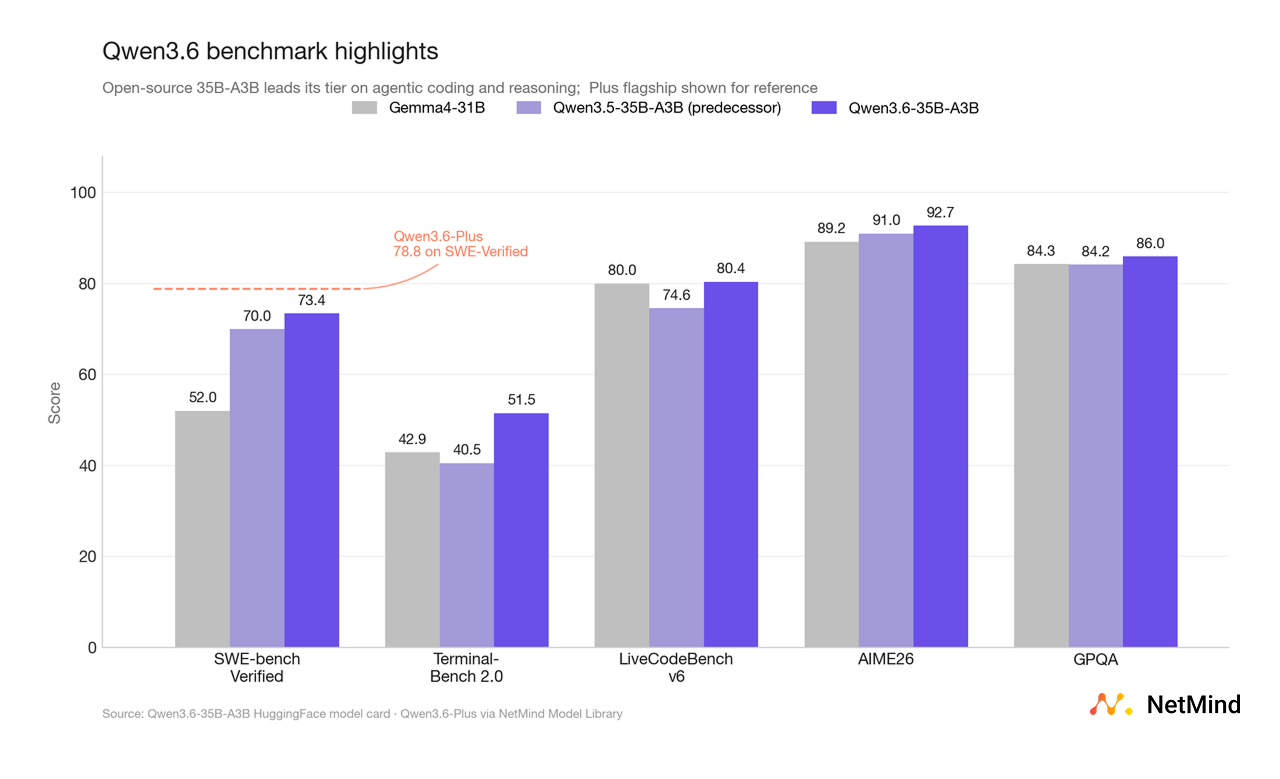
Both Qwen3.6-Plus and the open-source 35B-A3B post some of the strongest publicly reported coding and reasoning benchmarks in their respective tiers.
Qwen3.6-Plus (flagship)
Qwen3.6-35B-A3B (open-source, 3B active params)
For developers, the point is simpler: both are genuinely deployable agent-grade systems, not bench-optimized chat models. The 35B-A3B result is especially striking: frontier-class reasoning you can actually self-host.
Most model families ship one flagship and call the rest variants. Qwen3.6 takes a different approach: each of the three models is engineered for a distinct production pattern.

Qwen3.6-Plus is the hybrid-architecture flagship: linear attention combined with sparse mixture-of-experts routing, built for agentic coding, front-end development, and complex long-context tasks. Choose it when you want the model to spend minutes thinking and orchestrating, not milliseconds responding.
Qwen3.6-Flash is the commercial speed tier, sharing the same hybrid linear-attention + sparse MoE design. It supports a 1M-token context window with thinking mode, tuned for fast and cost-efficient inference on agentic and complex tasks. This is the always-on workhorse for real-time chat, in-IDE autocomplete, latency-bound agent loops, and high-volume production traffic.
Qwen3.6-35B-A3B is the open-source tier: Apache 2.0 license, 35B total parameters with 3B active per token, and a native context window of 262K tokens extensible to ~1M. You can fine-tune it, deploy it commercially, run it on-prem, and ship it inside your own product, with zero vendor lock-in.
That matters because production agent workloads are rarely uniform. Useful platforms need a flagship for the hard, high-stakes tasks, a speed tier for the volume of day-to-day interactions, and an open-source tier for fine-tuning, edge deployment, or sovereignty requirements. Qwen3.6 ships all three in one coherent family.
All three support function calling and reasoning out of the box, all three run on NetMind's ultra-efficient low-latency infrastructure, and all three share the same OpenAI-compatible endpoint.
NetMind gives you managed access to all three through the same OpenAI-compatible API surface you already use:
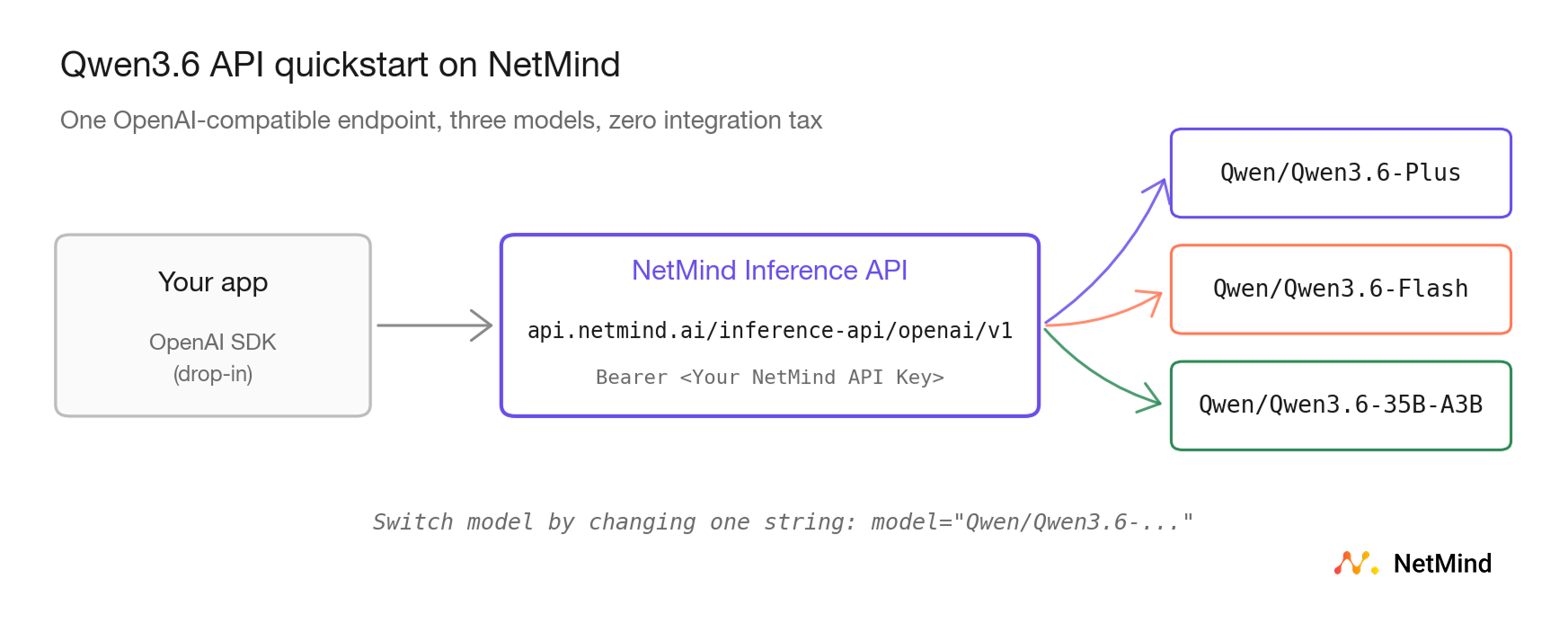
Swap the model name to pick the right tier. Everything else (your SDK, your prompts, your tool definitions, your agent loop) stays the same.
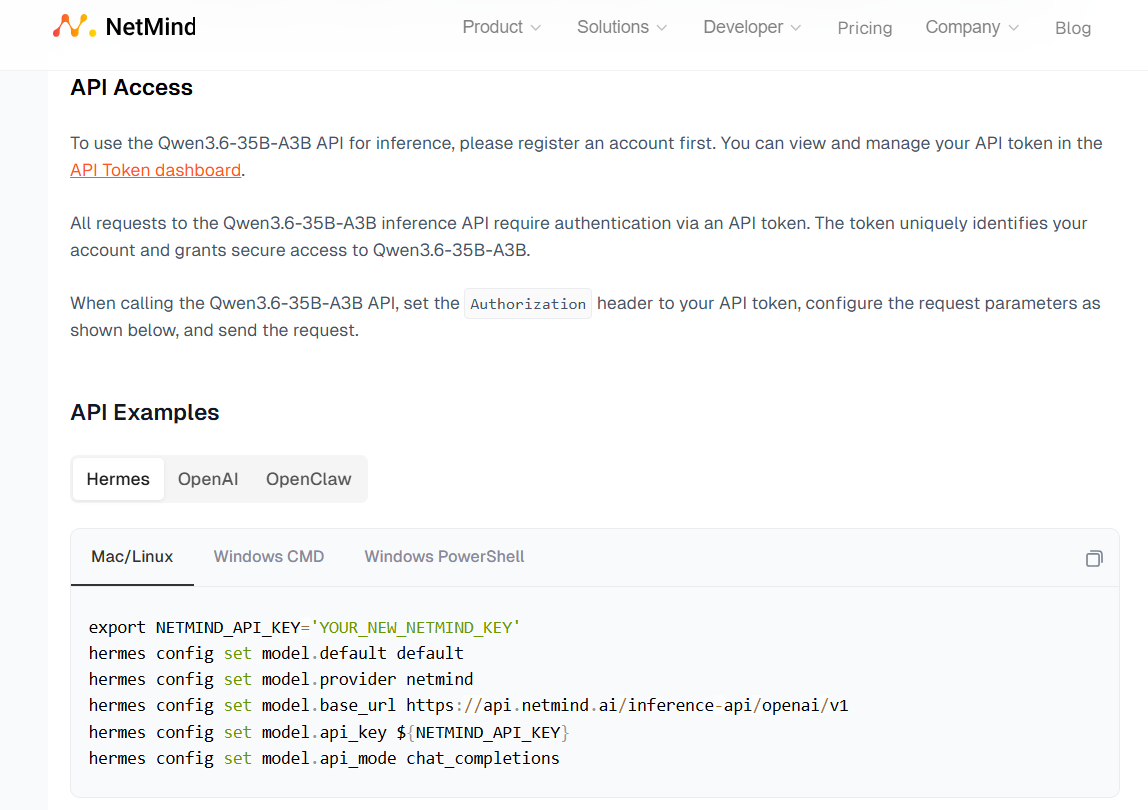
We know you want to power your most productive tools with Qwen as easily as possible, so we have provided ready-to-use code for you to copy and paste.
The Qwen3.6 lineup fits especially well into workflows where the model needs to do more than produce a polished answer:
With the full Qwen3.6 family now on NetMind, developers get a complete tier stack for agent work: frontier reasoning, cost-efficient scale, and open-source ownership when you need it.
The full Qwen3.6 family is now available in the NetMind Model Library:
If you build something with these, we want to see it. Join the discussion in our Reddit community.
User-Agent: