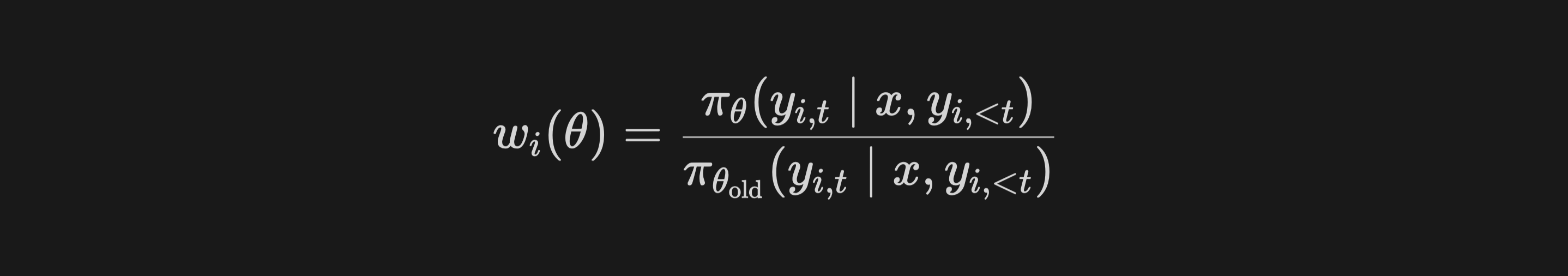
We've seen a clear path of advancements in Reinforcement Learning (RL) algorithms that have been proposed for fine-tuning LLMs: OpenAI uses PPO for ChatGPT to perform Reinforcement Learning with Human Feedback (RLHF), while DeepSeek Team found it more effective to conduct value estimation within a group of samples and propose Group Relative Policy Optimization (GRPO). However, extensive practice on training LLMs with GRPO exhibits severe stability issues, often resulting in irreversible model collapse. To train their latest Qwen3 series, Qwen Team proposes Group Sequence Policy Optimization (GSPO), a new RL algorithm for training large language models, and claims the training objective of GRPO, despite its empirical effectiveness, is ill-posed.
We've seen a clear path of advancements in Reinforcement Learning (RL) algorithms that have been proposed for fine-tuning LLMs: OpenAI uses PPO for ChatGPT to perform Reinforcement Learning with Human Feedback (RLHF), while DeepSeek Team found it more effective to conduct value estimation within a group of samples and propose Group Relative Policy Optimization (GRPO). However, extensive practice on training LLMs with GRPO exhibits severe stability issues, often resulting in irreversible model collapse. To train their latest Qwen3 series, Qwen Team proposes Group Sequence Policy Optimization (GSPO), a new RL algorithm for training large language models, and claims the training objective of GRPO, despite its empirical effectiveness, is ill-posed.
Full details can be found in the Qwen team’s original paper: Group Sequence Policy Optimization.
Qwen Team contends that GRPO’s instability is its incorrect application of token-level importance sampling weights. In RL, importance sampling is used to correct for differences between the behavior policy (the policy used to collect training data) and the target policy (the policy currently being optimized). When the two policies differ, importance sampling assigns weights to previously collected data samples, ensuring they're representative of the target policy you're trying to improve.
For LLMs, RL updates typically reuse responses generated by an older policy to save computational resources, which is a typical "off-policy" scenario. Importance sampling helps correct this mismatch and stabilize the training process. However, GRPO applies these weights separately to individual tokens rather than entire generated sequences, introducing significant variance and accumulated instability, especially when LLMs are generating longer sequences.
Formally, GRPO calculates importance weights for each generated sample at each token step separately:
Qwen Team noticed that with such importance weights applied on the training objective, since each token’s ratio is derived independently, high variance accumulates, destabilizing gradients, and causing eventual model collapse.
It introduces high-variance noise into the training gradients, which accumulates over long sequences and is exacerbated by the clipping mechanism.
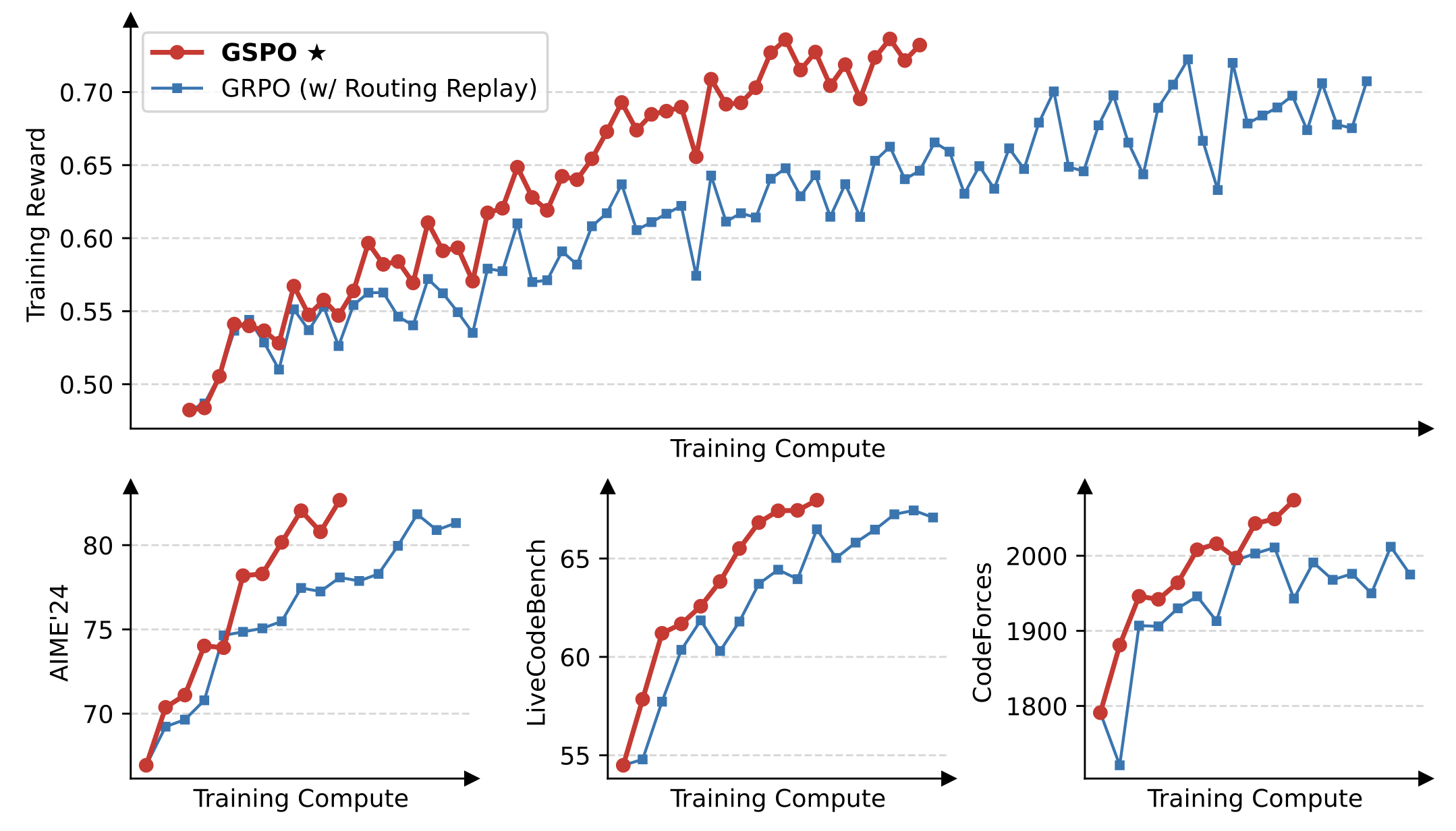
Qwen Team presents empirical evidence supporting their theoretical analysis, as shown in Figure 1. In all presented cases, their newly proposed algorithm GSPO possesses higher training efficiency than GRPO. In the task of CodeForces, GRPO converges to a score of under 2000, while GSPO continues to improve with more training compute, demonstrating better scaling ability.
Figure 1: Training curves comparing GSPO and GRPO (from original paper, section 5.1)
So what's the magic of GSPO to address these challenges? As the name suggests, GSPO simply shifts importance sampling to the sequence level, with the importance ratio based on sequence likelihood:
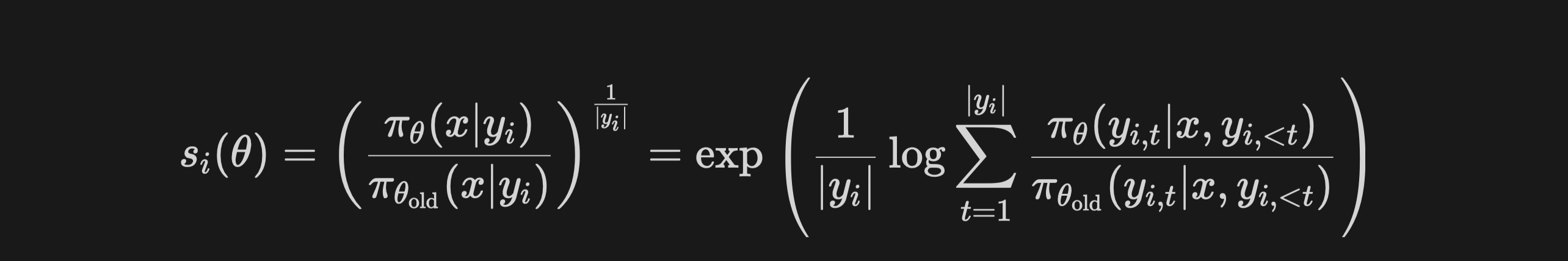
This design of sampling weights naturally mitigates variance accumulated by each single token, greatly stabilizing training. Note that the factor of exponent is for length normalization. Without length normalization, the likelihood changes of a few tokens can result in dramatic fluctuations of the sequence-level importance ratio, and the importance ratios of responses with different lengths will require varying clipping ranges in the objective function.
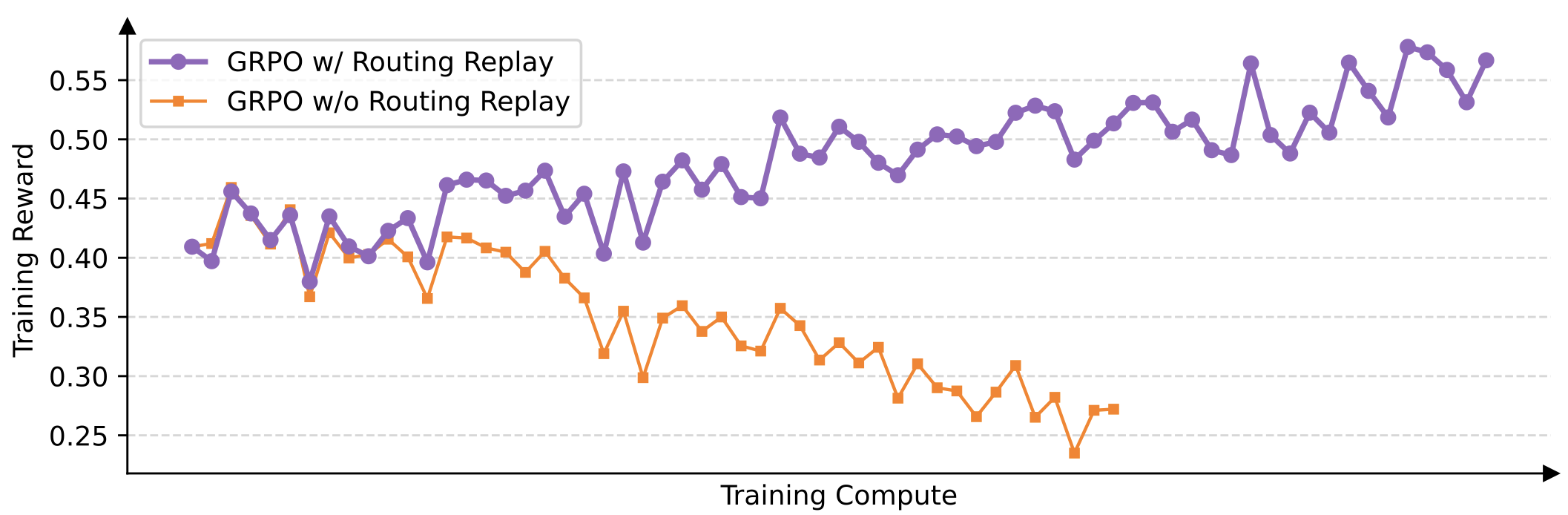
Experiments specifically conducted on Mixture-of-Experts (MoE) models further underline GSPO’s benefits. The sparse activation patterns of MoE models exacerbate instability issues in GRPO.
After one or more gradient updates, the experts activated for the same response can change significantly.
When Qwen Team were training the 48-layer Qwen3-30B-A3B-Base model with GRPO, after each RL gradient update and for the same rollout sample, they found that there were roughly 10% of the experts activated under the new policy were different from those under the old policy. This basically means that you are training different models with different data samples after each gradient update, which is undoubtedly ineffective. Before the insight of GSPO, they even adopted a trick called Routing Replay, which is forcing the target policy to activate the same experts as the old policy. In contrast, GSPO achieves stable convergence effortlessly without Routing Replay, eliminating unnecessary complexity and retaining the full potential of MoE structure.
Figure 2: The Routing Replay strategy plays a critical role in the normal convergence of the GRPO training of MoE models (from original paper, section 5.3)
There’s already broad agreement that applying RL in the post-training stage is crucial for boosting an LLM's reasoning capabilities. As extensive experiments from the paper confirm that GRPO’s token-level importance sampling approach can be unstable and inefficient, GSPO’s sequence-level importance sampling is probably going to be the new standard for post-training RL. GSPO might also be the reason for the huge success of Qwen3 series of models.
User-Agent: