
Nine years ago, at NeurIPS 2016, Turing Award winner Yann LeCun famously described machine learning as a three-layered cake. At the base lies unsupervised learning—the bulk of the cake—trained on vast amounts of raw data. Then comes supervised learning, the frosting, which fine-tunes models for specific tasks with labeled examples. At the very top is reinforcement learning, the cherry that further refines model behavior through reward signals. Fast forward to nearly a decade, and the development of large language models (LLMs) has followed this recipe exactly. First came unsupervised pretraining through next-token prediction. Then, supervised fine-tuning (SFT) aligned models to specific use cases. Now, how can we further push the boundaries of LLMs? The answer is clear: reinforcement fine-tuning (RFT).
Nine years ago, at NeurIPS 2016, Turing Award winner Yann LeCun famously described machine learning as a three-layered cake. At the base lies unsupervised learning—the bulk of the cake—trained on vast amounts of raw data. Then comes supervised learning, the frosting, which fine-tunes models for specific tasks with labeled examples. At the very top is reinforcement learning, the cherry that further refines model behavior through reward signals.
Fast forward to nearly a decade, and the development of large language models (LLMs) has followed this recipe exactly. First came unsupervised pretraining through next-token prediction. Then, supervised fine-tuning (SFT) aligned models to specific use cases. Now, how can we further push the boundaries of LLMs? The answer is clear: reinforcement fine-tuning (RFT).
SFT has become the standard method for adapting general-purpose LLMs to specific tasks. It teaches models how to follow instructions, align to structured formats, and perform better in domain-specific contexts. But SFT comes with a tradeoff: it typically requires carefully curated, labeled data, and its performance is obviously capped by the quality of the data.
As tasks grow more complex and nuanced, acquiring enough labeled examples for effective SFT becomes harder—and in some cases, impractical. RFT builds on SFT by adding feedback loops that reward desirable outputs. While SFT teaches a model using static, labeled examples, RFT makes the training process interactive: the model generates outputs, and a grader scores them based on defined criteria such as accuracy, structure, or policy alignment.
Grading mechanisms vary and can include:
RFT is especially powerful when the task has clearly verifiable outcomes and these outcomes can be verified with automated graders instead of human reviewers. During RFT, the model continuously updates its parameters based on the reward signals provided by the grader. This allows the model to adjust its strategy and generate higher-quality responses that better fulfill the instructions specified in the task. Hence, getting the most from RFT requires two core ingredients: a well-scoped task and a reliable grader.
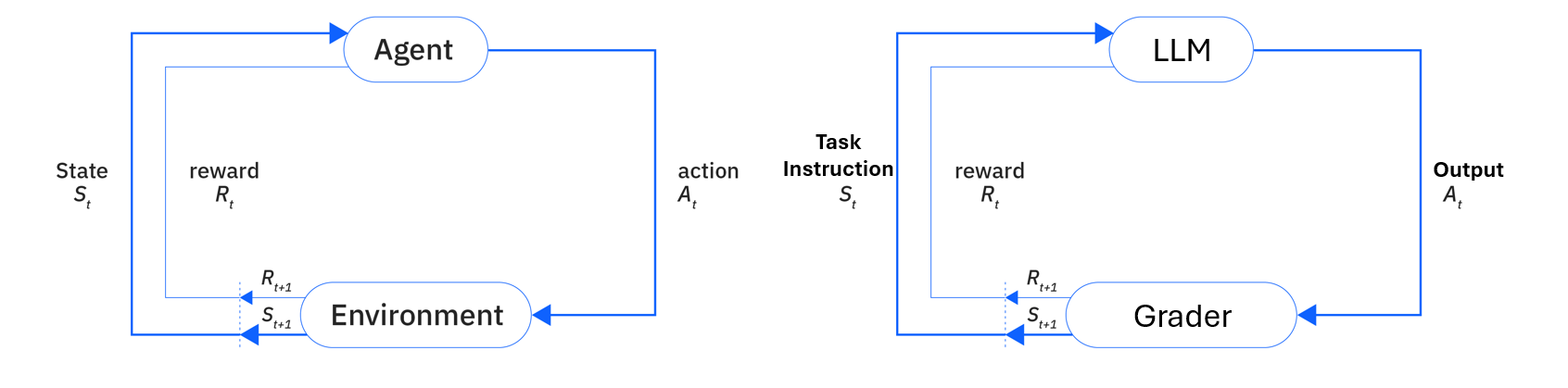
A comparison between RL (left) and RFT (right)
RFT thrives when a model already performs somewhat well, and the task has clear success criteria. “Somewhat well” means that the model is already capable of producing meaningful outputs for the given task, even if those outputs are not always correct. This baseline capability is essential—RFT relies on feedback signals to guide the model’s learning. If the model’s outputs are consistently poor and never receive any positive reward, it won’t have the signal it needs to improve. Sometimes, you’ll need to revise the prompt, break tasks into smaller components, or enrich the input context to make the problem learnable.
The grader is the heart of RFT. It serves as the source of feedback that shapes the model's learning trajectory. A robust grader should provide consistent, informative, and task-aligned reward signals—enough to distinguish between better and worse outputs, but not so rigid that it discourages useful variation. As mentioned before, this could mean validating structured formats, checking code correctness, or evaluating response quality using another LLM. Crucially, the grader must be reliable and scalable, so that feedback can be applied at the training scale without requiring constant human intervention.
RFT isn’t a silver bullet—but if your model’s output quality varies and you can define success clearly, it may be exactly what you need to solve a specific task like a human expert.
We highly recommend considering RFT if:
Reinforcement fine-tuning isn’t just about squeezing extra performance from your model. Its philosophy is to enhance the performance of the model through its own exploration and exploitation, which we believe reflects the core of intelligence. RFT also gives you the tools to define what "good" means in your own domain—and systematically train your model to deliver it.
If SFT got you 80% of the way there, RFT might be the final 20% that takes you across the finish line.
User-Agent: