 An interesting “Aha Moment” of an intermediate version of DeepSeek-R1-Zero. The model learns to rethink using an anthropomorphic tone
An interesting “Aha Moment” of an intermediate version of DeepSeek-R1-Zero. The model learns to rethink using an anthropomorphic toneLess than a month ago, DeepSeek made headlines with its DeepSeek-V3 model. Today, the open-source DeepSeek project has once again astounded the global AI community by releasing DeepSeek-R1—a model that maintains DeepSeek’s remarkable cost-effectiveness while making a significant leap forward in technical innovation. If you’re interested in the model’s technical details, you can keep reading this article—where we will interpret and break down the R1 technical report.
DeepSeek proves that open-source AI is “no longer just a non-commercial research initiative but a viable, scalable alternative to closed models” like OpenAI’s GPT, says our CCO Seena Rejal in a recent CNBC article.
Here at NetMind Power, we are pleased to offer DeepSeek-R1 (and also DeepSeek-v3) via our Model API to all who wish to harness its capabilities in production settings. If you’d like to try R1 right away, feel free to visit this link.
Late last year, DeepSeek-V3 demonstrated how top-tier performance—rivaling models like GPT-4o and Claude Sonnet 3.5—could be achieved at notably low training expense. The newly released DeepSeek-R1 continues in that direction, requiring roughly one-tenth the training budget of comparable large language models like OpenAI's o1. How cheap is it? With our Model API at NetMind Power, DeepSeek-R1 costs just $2.19 per million output tokens currently, compared to $60.00 for OpenAI’s o1—nearly 30 times cheaper! Even better, DeepSeek-R1 remains open source, inspiring many observers to call it the next serious contender to match or even surpass OpenAI’s o1 model.
According to the technical report, the DeepSeek team experimented with multiple training strategies for R1. The most revolutionary method—and the one we’ll focus on here—is R1-Zero, which leverages a “pure reinforcement learning” technique to enhance reasoning capacity at scale.
Typical large-model training methods often rely on supervised fine-tuning (SFT) with extensive Chain of Thought (CoT) examples or sophisticated reward models, sometimes combined with Monte Carlo Tree Search (MCTS). R1-Zero took an entirely different route—no pre-defined CoT prompts, just two simple types of rewards:
Using these straightforward signals, R1-Zero samples and compares its outputs in batches under GRPO (Group Relative Policy Optimization)—an efficient process for updating policy parameters. Despite its simplicity, this method produced several notable advantages:
An interesting “Aha Moment” of an intermediate version of DeepSeek-R1-Zero. The model learns to rethink using an anthropomorphic tone
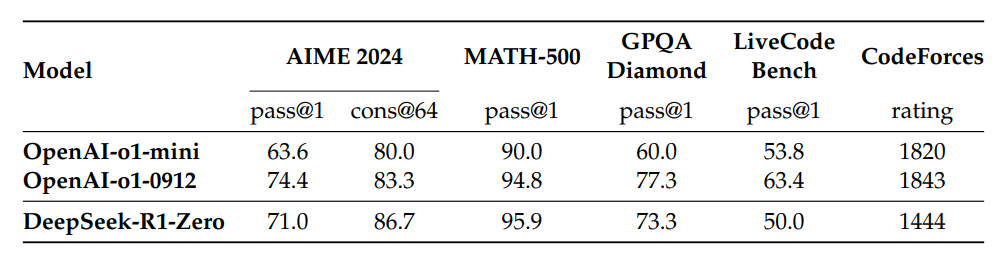
DeepSeek-R1-Zero performs comparably or even better than OpenAI-o1 in some benchmarks
Interestingly, R1-Zero can outperform some top models when it’s allowed multiple attempts at the same question; in AIME 2024, its accuracy skyrocketed to 86.7%—higher than some versions of OpenAI o1. This suggests R1-Zero has cultivated a deeper, more general approach to reasoning.
Moreover, R1-Zero’s lean reward system minimizes reward hacking, where a model simply learns to trick complex reward functions rather than truly improving its reasoning. Because the reward signals are so straightforward, R1-Zero’s achievements seem authentic. Researchers see this approach as a potential stepping stone toward AGI, hinting that purely RL-driven training could unleash more “natural” reasoning in AI.
While powerful in its reasoning capabilities, R1-Zero often produces content that is not suitable for easy reading. Its responses may blend multiple languages or lack proper formatting, making it difficult for users to follow. To address these issues, DeepSeek team developed cold-start data for DeepSeek-R1 with a focus on readability. They designed a clear output pattern that includes a summary at the end of each response and filters out content that isn't user-friendly. This approach aims to produce more coherent, interpretable chains of thought without sacrificing the power and flexibility that define the DeepSeek models, and is published as DeepSeek R1.
The release of DeepSeek-R1 has once again demonstrated how low-cost, high-performance AI models can be achieved—while also showcasing the huge potential of pure reinforcement learning.
As DeepSeek is an open-source endeavor, NetMind Power is proud to support the open-source DeepSeek project by offering DeepSeek-R1 through our Model API. If you’d like to explore the next frontier of AI reasoning, we invite you to visit our website or reach out to our team for more information. From complex math problems to challenging coding tasks, see how this new model might power your AI journey forward.
