
Large language models (LLMs) are transforming the way we interact with data, but true breakthroughs never happen in isolation. They are driven by high-quality datasets and pioneering research efforts that push the boundaries of what AI can achieve. Among the many challenges LLMs face, generating accurate and executable visualization code is one of the most critical for real-world applications in data science.
The newly released paper accepted in EMNLP 2025, VisCoder: Fine-Tuning LLMs for Executable Python Visualization Code Generation, takes a step forward by introducing a large-scale dataset and fine-tuned models tailored for data visualization tasks. At NetMind, we are proud to be at the forefront of this journey. Our CEO, Kai Zou, is a co-author of this work, reflecting our company’s mission to drive cutting-edge AI research and to empower the global community with tools that are open, impactful, and future-focused.
In this blog, we’ll take you through a quick overview of the paper’s core ideas and contributions.
At first glance, generating charts from data might seem like a straightforward code-generation task. Yet visualization poses unique challenges that go beyond simply writing syntactically correct code. It requires the model to bridge three distinct modalities: the language of user instructions, the structure of the underlying dataset, and the visual output that must be presented correctly and capture the intended meaning.
This complexity exposes the limitations of current LLMs. Even when a model produces code that looks correct without any execution errors, the resulting chart may fail in practice, generating blank or malformed plots, or misrepresenting the semantics of the request. Apparently, part of the problem lies in the training data. Existing datasets rarely enforce supervision that checks whether the generated code is both executable and visually accurate. Moreover, they offer little guidance for models to recover when things go wrong, leaving them ill-prepared for the iterative process of debugging that is so essential to real-world coding.
To close this gap, the paper introduces VisCode-200K, a large-scale dataset containing over 200,000 supervised examples. The dataset is constructed from two complementary sources that together capture both the generation and correction aspects of visualization code.
The first source is executable visualization code collected from open-source Python repositories. These snippets are carefully filtered and validated across widely used libraries, including Matplotlib, Seaborn, and many others. Each code block is paired with its rendered plot, and natural language instructions are automatically generated with the assistance of LLMs. This ensures that every example links code, visual output, and descriptive instructions in a coherent way.
The second source, multi-turn revision dialogues, comes from the Code-Feedback dataset, which provides multi-turn debugging dialogues. These dialogues record realistic developer interactions, where faulty code is iteratively revised based on runtime error messages and follow-up feedback. By incorporating this data, the models can be trained to generate multi-round refinement of their code and improve it iteratively through feedback, much like a human developer engaged in debugging.
Together, these two components create a dataset that supports both single-shot code generation and multi-round correction, laying the foundation for more reliable and semantically accurate visualization code.
With VisCode-200K, the authors also fine-tuned the open-source Qwen2.5-Coder-Instruct model, producing VisCoder, available in both 3B and 7B parameter scales.
The model was tested on PandasPlotBench, a benchmark designed to evaluate whether models can generate executable, semantically accurate visualization code across multiple plotting libraries.
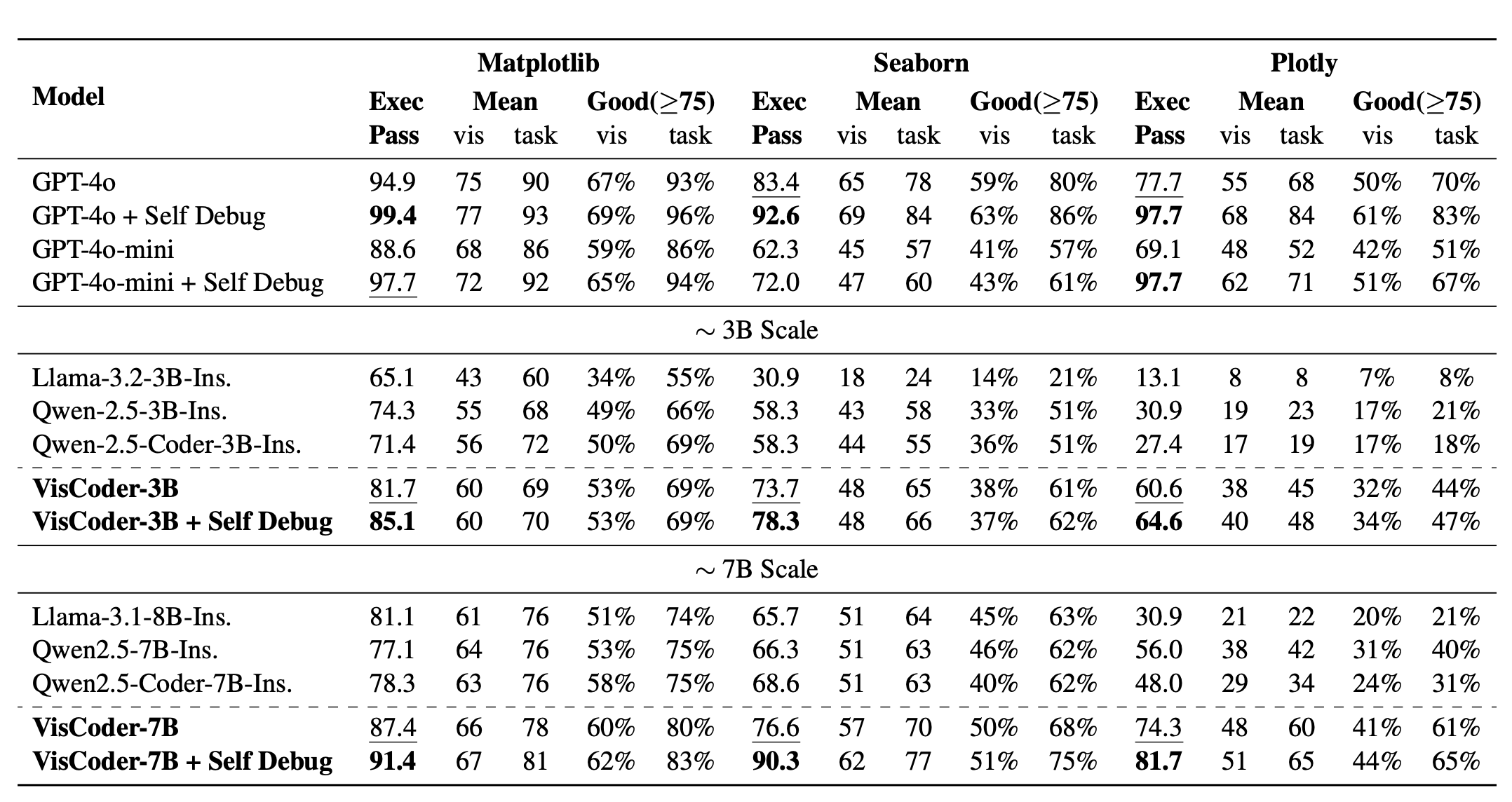
The experiments show that VisCoder delivers substantial improvements over existing open-source baselines. At both the 3B and 7B parameter scales, the model achieved execution pass rate gains of +19.6 and +14.5 points compared to its Qwen2.5-Coder base models. These results highlight the effectiveness of domain-specific instruction tuning when it is grounded not only in code syntax but also in execution outcomes and visual accuracy.
Another major contribution is the introduction of a self-debugging evaluation protocol, which allows models to revise their outputs over multiple rounds using execution traces. In this setup, VisCoder demonstrated remarkable reliability, achieving over 90% execution pass rates on Matplotlib and Seaborn. This mirrors the natural workflow of a human developer: writing code, testing it, observing the errors, and iteratively correcting them, showing that feedback-driven refinement is crucial for practical performance.
Perhaps most striking is how VisCoder compares with proprietary closed-source models. At the 7B scale, VisCoder was able to outperform GPT-4o-mini on Seaborn and Plotly. When combined with the self-debugging protocol, it even narrowed the gap with GPT-4o, approaching its performance across multiple libraries. Even the smaller VisCoder-3B surpassed GPT-4o-mini in certain benchmarks, underscoring how open-source models, when carefully tuned with the right data, can compete with and even surpass state-of-the-art commercial models.

The significance of this work lies in how it frames visualization code generation as a distinct and challenging problem for LLMs. The dataset VisCode-200K provides a resource that can help the community study this problem in a more systematic way. The dataset itself is already a valuable contribution, as it combines real visualization code with rendered outputs and debugging traces, offering a foundation for future research.
Building on this dataset, the fine-tuned VisCoder model demonstrates how domain-specific training can lead to measurable improvements. While not a final solution, these experiments highlight the benefits of grounding models in executable outcomes and suggest directions for making visualization code generation more reliable. In this sense, the work contributes both a practical tool and useful insights for ongoing research in the field.
👉 Explore the project here: VisCoder Project Page
👉 Full paper on arXiv: VisCoder: Fine-Tuning LLMs for Executable Python Visualization Code Generation
User-Agent: